Introduction
A lot of workloads are driven by peak consumption. From my experience, there aren’t the amount of workloads that have a constant performance need are in the minority. Now here comes the interesting opportunity when leveraging serverless architectures… Here you only pay for your actual consumption. So if you tweak your architecture to leverage this, then you can get huge gains!
For today’s post, I’ll be using VMchooser once again as an example. A lot has changed since the last post on the anatomy of this application. Here is an updated drawing of the high level architecture ;
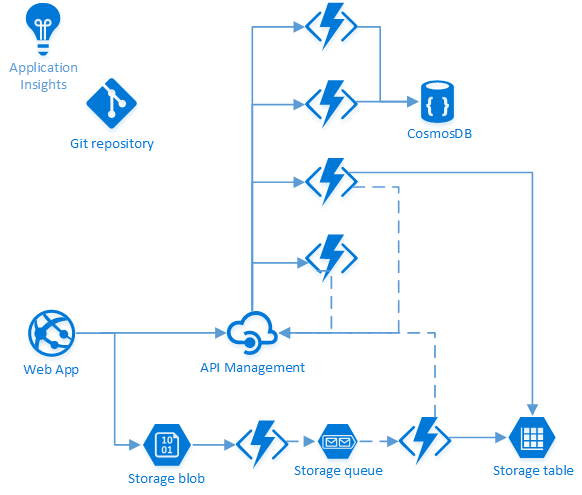
Underneath you can see the flow that’ll be used when doing a “Bulk Mapping” (aka “CSV Upload”). The webapp (“frontend”) will store the CSV as a blob on the storage account. Once a new blob arrives, a function will be triggered that will examine the CSV file and put every entry…
View original post 953 more words
