Durable Task Scheduler Consumption SKU is Now Generally Available

The Durable Task Scheduler Consumption SKU has reached General Availability. If you’ve been waiting for a production-ready, pay-per-use orchestration backend for your durable workflows and AI agents on Azure — this is it. For anyone building on Azure Functions or Container Apps, this is worth paying attention to.
What is the Durable Task Scheduler?
The Durable Task Scheduler is a fully managed orchestration backend for durable execution on Azure. It handles task scheduling, state persistence, fault tolerance, and monitoring — so your workflows and agent sessions can reliably resume and run to completion through process failures, restarts, and scaling events, without you managing your own execution engine or storage backend.
It works across Azure compute environments:
- Azure Functions — via the Durable Functions extension, across all plan types including Flex Consumption
- Azure Container Apps — using Durable Functions or Durable Task SDKs with built-in workflow support and auto-scaling
- Any compute — AKS, App Service, or any environment running the Durable Task SDKs (.NET, Python, Java, JavaScript)
Why the Consumption SKU Matters
Until this GA, the pay-per-use Consumption SKU was in public preview (since November 2025), while the Dedicated SKU was already the GA option for reserved capacity and higher-scale workloads. The Consumption SKU flips the model for lower-scale and variable-usage scenarios: you’re charged only for actions dispatched — with no idle costs, no minimum commitments, and no throughput to pre-size. You still pay separately for the Azure compute hosting your workflows; what the Consumption SKU removes is preprovisioned scheduler capacity and its associated idle cost.
This makes it a natural fit for workloads with spiky or unpredictable usage:
- AI agent orchestration — multi-step agent workflows calling LLMs, retrieving data, and taking actions on demand
- Event-driven pipelines — processing queues, webhooks, or streams with reliable checkpointing
- API-triggered workflows — user signups, payment flows, and other request-driven processing
- Distributed transactions — retry and compensation logic across microservices using durable sagas
The Consumption SKU supports up to 500 actions per second and 30 days of data retention, with a built-in dashboard for filtering orchestrations, drilling into execution history, viewing visual Gantt and sequence charts, and managing instances (pause, resume, terminate, raise events) — all secured with Entra ID and RBAC. No SAS tokens or access keys. If you need more throughput or longer retention, Dedicated remains the better fit.
Read the Full Announcement
For the complete details — including billing specifics, GA hardening changes from the preview, and links to getting started — read the full announcement:
👉 The Durable Task Scheduler Consumption SKU is Now Generally Available — Azure App Service Blog
Enjoy!
References
- Durable Task Scheduler Consumption SKU — GA Announcement — Full announcement from the Azure Functions product team
- Durable Task Scheduler documentation — Official docs
- Getting started with Durable Task Scheduler — Quickstart guide
- Durable Task Scheduler samples — Sample projects
- Consumption SKU pricing — Billing details
TypeScript 6.0: A Transitional Release That Sets the Stage for a Big Rewrite

Earlier this week, Microsoft released TypeScript 6.0. This is a major milestone for the language, not because of what it adds, but instead, this release is significant because it represents the final major version built on the existing JavaScript-based codebase. Starting with TypeScript 7.0, the language is heading into a new era.
A Release Designed for Transition
According to Microsoft’s announcement, TypeScript 6.0 is primarily focused on preparing developers for the upcoming architectural shift. Beginning with version 7.0, the TypeScript team will:
- Rewrite the compiler and language tooling in Go
- Deliver native performance improvements
- Introduce shared-memory multithreading
- Move away from the legacy JavaScript implementation entirely
This makes 6.0 less of a feature-driven release and more of a bridge to the future.
What’s New in TypeScript 6.0
While transitional in nature, the release still includes several meaningful updates:
- Updated DOM types to align with the latest web standards
- Improved inference for contextually sensitive functions
- Support for subpath imports, enabling cleaner module resolution
- A new migration-assist flag to help developers prepare for the 6.0 to 7.0 upgrade path
These improvements aim to smooth the road ahead as the ecosystem prepares for the Go-based compiler.
Deprecations
Microsoft notes that several features are now deprecated in 6.0 and will be fully removed in TypeScript 7.0. These changes reflect the evolving JavaScript ecosystem and the need to modernize the language’s foundations. Developers can still use deprecated features in 6.0, but they should expect migration work before adopting 7.0.
Enjoy!
References
Bringing Real‑Time Intelligence to Airport Data Streams (Type-B Messages) – Part 2: Setting It Up in Microsoft Fabric
In Part 1, I covered the architecture, the event model, and why airport baggage tracking makes such a compelling real-time analytics scenario. In this post, I want to get hands-on and walk through actually setting this up inside Microsoft Fabric — from creating the workspace artifacts all the way through to running the simulator and querying live events.
Let’s get into it.
Prerequisites
Before you start, you’ll need:
- A Microsoft Fabric workspace with the Real-Time Intelligence workload enabled (F2 or higher capacity, or a Fabric trial)
- An Azure Event Hubs namespace with a hub (or you can use Fabric’s built-in custom endpoint in Eventstream — more on that below)
- The Baggage Handling Simulator cloned locally, and Python 3.10+ was installed
If you want to follow along with Azure Event Hubs as the source, a Basic-tier namespace is fine for dev/test. If you’re going direct to Fabric Eventstream, you won’t need Event Hubs at all.
Architecture Overview
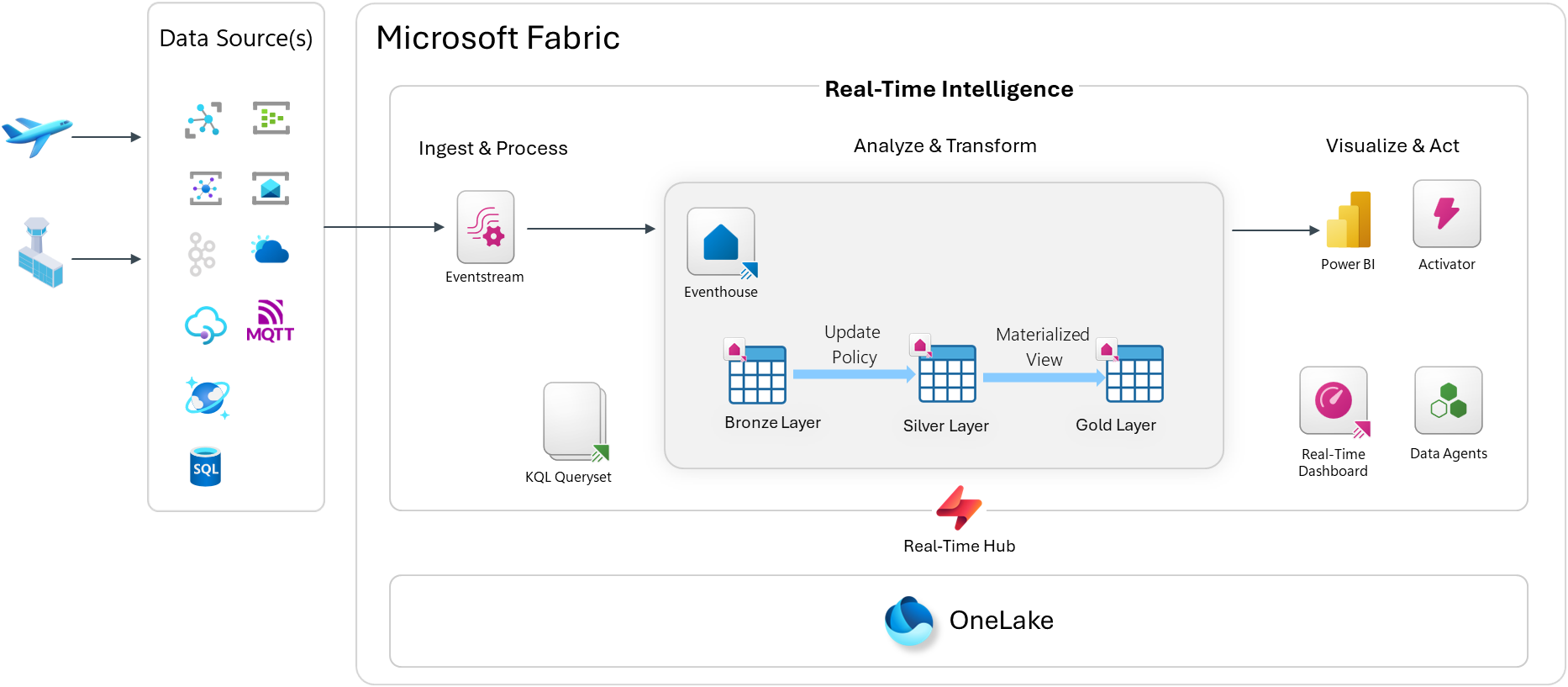
Step 1: Create the Fabric Workspace Artifacts
Start by creating a new workspace if you don’t already have one. I created on called “Airport Operations Demo”. Open up your Fabric workspace, and you’ll need to create four main artifacts:
- Eventhouse (your KQL database)
- Eventstream (ingestion and routing)
- KQL Queryset (ad-hoc queries and saved analytics)
- Real-Time Dashboard (live visualization)
Create the Eventhouse
From the Fabric workspace, click New → Eventhouse. Give it a name like Airport-Eventhouse. This creates an Eventhouse and a default KQL database inside it.

Once provisioned, open the Eventhouse and navigate to the KQL database. This is where we’ll define the table schemas.
Step 2: Create the Table Schema
We’ll use a Bronze / Silver / Gold medallion structure inside the KQL database. Bronze tables hold raw events exactly as ingested. Silver tables hold cleaned and enriched data. Gold tables hold pre-aggregated views.
NOTE: Due to the number of schema objects, I’m going to be showing a subset across each section below. Please go here to see the rest of the KQL scripts to be applied: https://github.com/calloncampbell/BaggageHandling-TypeB-Simulator/blob/main/kql
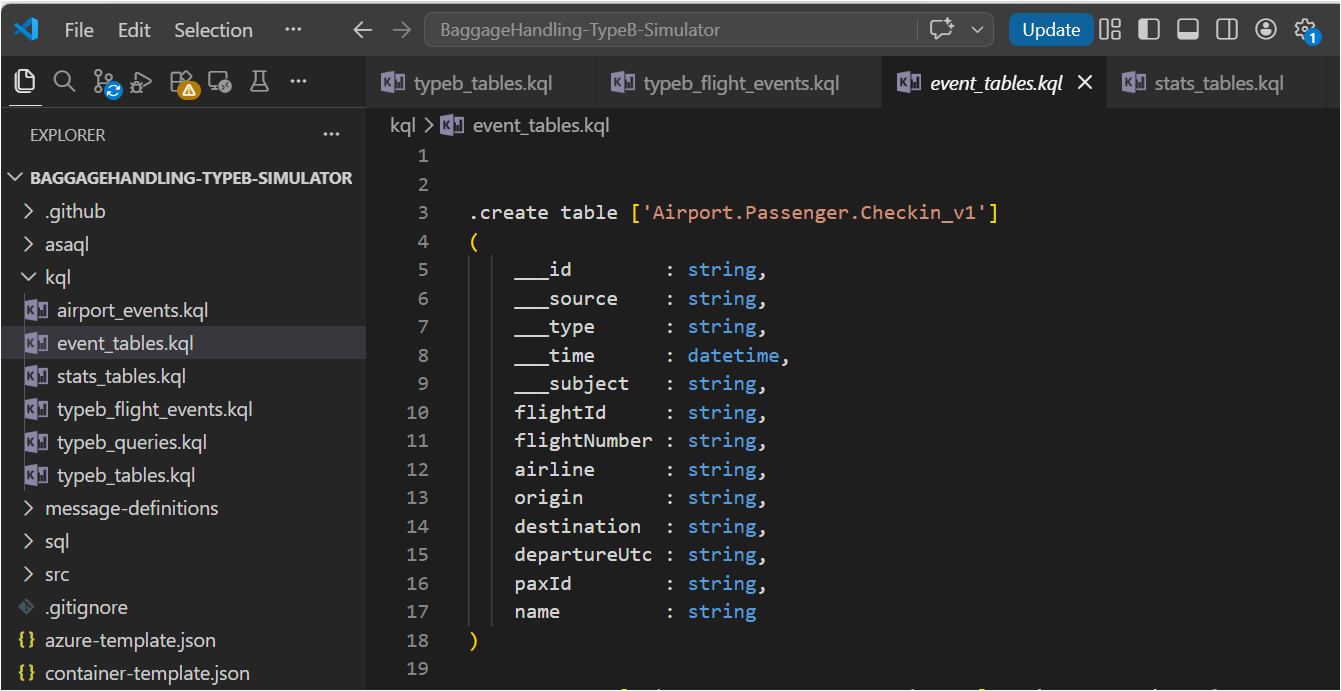
Open the Explore your data pane in the KQL database and run the following to create the Bronze tables:
// Bronze: raw airport events.create table airport_events ( id: string, source: string, specversion: string, type: string, datacontenttype: string, dataschema: string, subject: string, ['time']: datetime, data: dynamic, seriesclock: datetime).alter table airport_events policy streamingingestion enable // Bronze: raw flight operational events.create table typeb_flight_events ( id: string, source: string, specversion: string, type: string, datacontenttype: string, dataschema: string, subject: string, ['time']: datetime, data: dynamic, seriesclock: datetime).alter table typeb_flight_events policy streamingingestion enable // Bronze: event tables .create table ['Airport.Passenger.Checkin_v1']( ___id : string, ___source : string, ___type : string, ___time : datetime, ___subject : string, flightId : string, flightNumber : string, airline : string, origin : string, destination : string, departureUtc : string, paxId : string, name : string)
Ingestion Mapping
When events arrive as JSON via Eventstream, you’ll want an ingestion mapping so the raw JSON gets parsed correctly into the table columns:
// Ingestion mapping for airport events.create-or-alter table airport_events ingestion json mapping "airport_events_mapping"```[ { "column": "id", "path": "$.id", "datatype": "string", "transform": null }, { "column": "source", "path": "$.source", "datatype": "string", "transform": null }, { "column": "specversion", "path": "$.specversion", "datatype": "string", "transform": null }, { "column": "type", "path": "$.type", "datatype": "string", "transform": null }, { "column": "datacontenttype", "path": "$.datacontenttype", "datatype": "string", "transform": null }, { "column": "dataschema", "path": "$.dataschema", "datatype": "string", "transform": null }, { "column": "subject", "path": "$.subject", "datatype": "string", "transform": null }, { "column": "time", "path": "$.time", "datatype": "datetime", "transform": null }, { "column": "data", "path": "$.data", "datatype": "dynamic", "transform": null }]```// Ingestion mapping for flight events.create-or-alter table typeb_flight_events ingestion json mapping "typeb_flight_events_mapping"```[ { "column": "id", "path": "$.id", "datatype": "string", "transform": null }, { "column": "source", "path": "$.source", "datatype": "string", "transform": null }, { "column": "specversion", "path": "$.specversion", "datatype": "string", "transform": null }, { "column": "type", "path": "$.type", "datatype": "string", "transform": null }, { "column": "datacontenttype", "path": "$.datacontenttype", "datatype": "string", "transform": null }, { "column": "dataschema", "path": "$.dataschema", "datatype": "string", "transform": null }, { "column": "subject", "path": "$.subject", "datatype": "string", "transform": null }, { "column": "time", "path": "$.time", "datatype": "datetime", "transform": null }, { "column": "data", "path": "$.data", "datatype": "dynamic", "transform": null }]```
Silver Layer via Update Policy
Rather than running a scheduled job to promote Bronze to Silver, Update Policies do this automatically at ingest time. Define a function that transforms the raw event, then attach it as a policy. In the following example I’ve embedded my KQL query directly in the policy. You could instead create a KQL function for this query and then reference it here instead.
.alter table ['Airport.Passenger.Checkin_v1'] policy update```[ { "IsEnabled": true, "Source": "airport_events", "Query": "let bags = airport_events| where type == 'Airport.Passenger.Checkin' and isnull(array_length(data))==true;let arrays = airport_events| where type == 'Airport.Passenger.Checkin' and isnull(array_length(data))==false| mv-expand data;bags| union arrays| project ___id = tostring(id), ___source = tostring(source), ___type = tostring(type), ___time = todatetime(['time']), ___subject = tostring(subject), flightId = tostring(data.flightId), flightNumber = tostring(data.flightNumber), airline = tostring(data.airline), origin = tostring(data.origin), destination = tostring(data.destination), departureUtc = tostring(data.departureUtc), paxId = tostring(data.paxId), name = tostring(data.name)", "IsTransactional": false, "PropagateIngestionProperties": false }]```// Legacy table name aliases (functions for backward compatibility).create-or-alter function airport_passenger_checkin() { ['Airport.Passenger.Checkin_v1']}
Every event that lands in BaggageEvents_Bronze is automatically transformed and inserted into BaggageEvents_Silver — no pipelines, no orchestration.
Gold Layer via Materialized Views
Materialized Views pre-aggregate data so your dashboard queries are fast, even against billions of rows. Here is a sample useful ones for this use case:
// Gold: latest status per flight.create materialized-view flights_current on table flights { flights | summarize arg_max(updated, *) by flightId}
When we’re done, we should see our database schema of tables, materialized views, and functions:
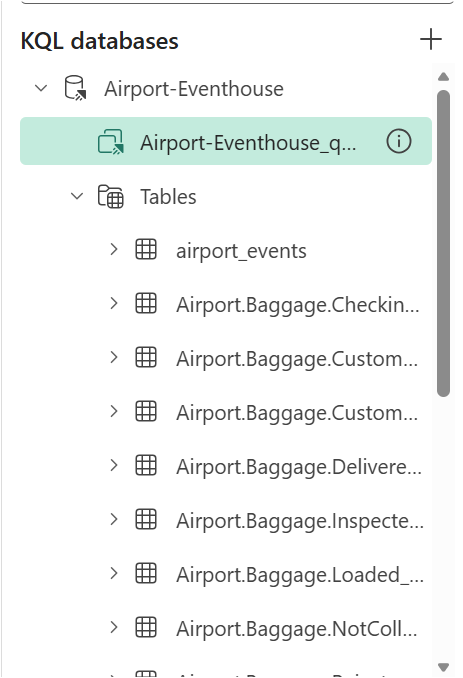
Step 3: Configure the Eventstream
Now wire up the ingestion pipeline. In your Fabric workspace, click New → Eventstream and name it evs-airport-events.
Option A: Azure Event Hubs as Source (what I’m doing)
If you’re publishing events from the Baggage Handling Simulator to Azure Event Hubs:
- In the Eventstream canvas, click Add source → Azure Event Hubs
- Enter your Event Hubs namespace, hub name, and connection string (or use a Fabric connection)
- Set the consumer group — use
$Defaultfor dev/test - Set the data format — use
json
Option B: Custom Endpoint (no Event Hubs needed)
Fabric Eventstream also exposes a custom endpoint — an HTTPS or AMQP ingest URL you can publish CloudEvents directly to, without needing an external Event Hubs namespace. This is great for demos and local testing.
- Click Add source → Custom endpoint
- Copy the connection string — you’ll use this in the simulator config
Add the Eventhouse Destination
- Click Add destination → Eventhouse
- Select the
Airport-EventhouseEventhouse and the KQL database - Select the
airport_eventstable and theairport_events_mappingingestion mapping
Once everything is setup, this is what we should see:
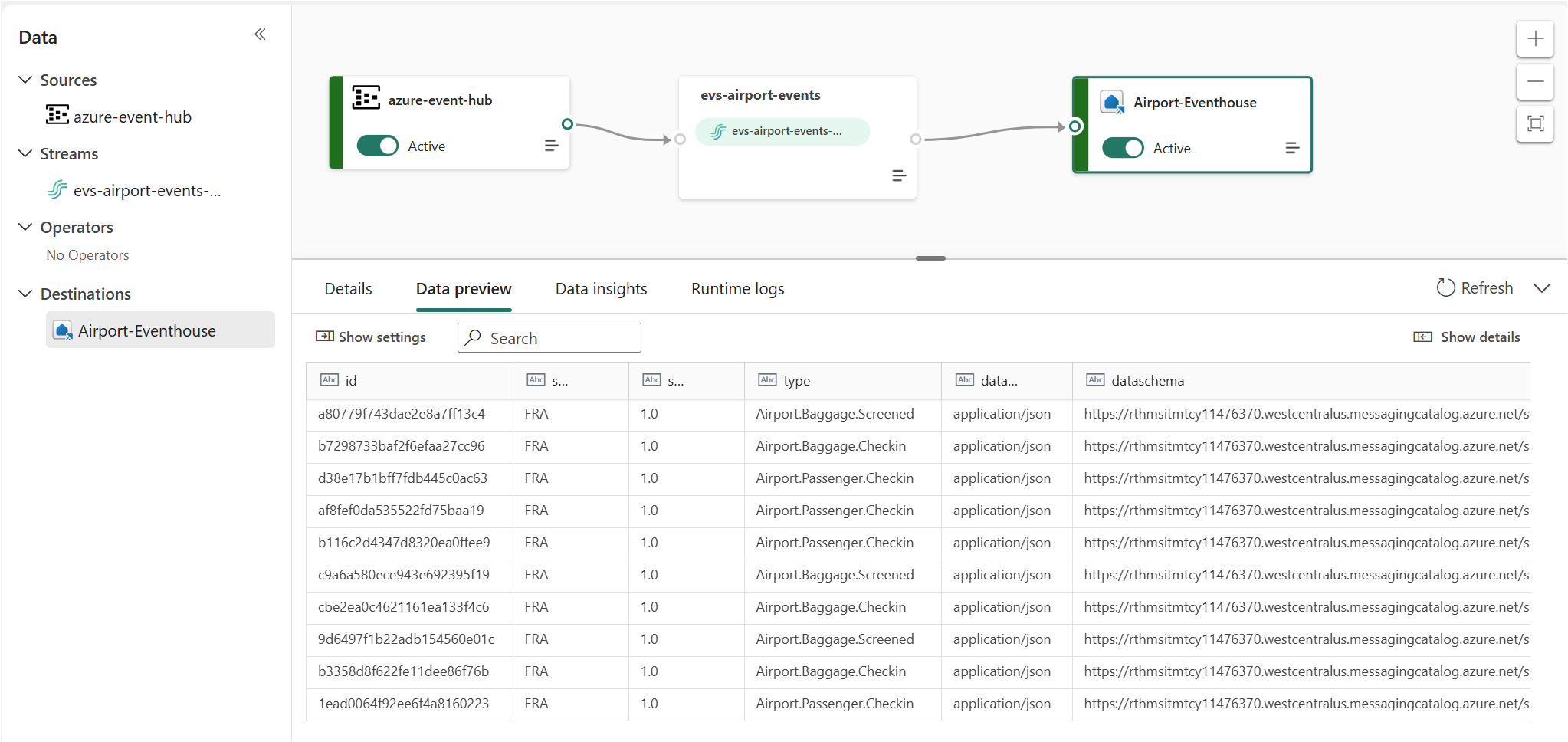
One of the nice features in Fabric Eventhouse that we don’t see in Azure Data Explorer is the Entity Diagram, which is currently in preview. Go back to your KQL database main view and click on the entity diagram button:
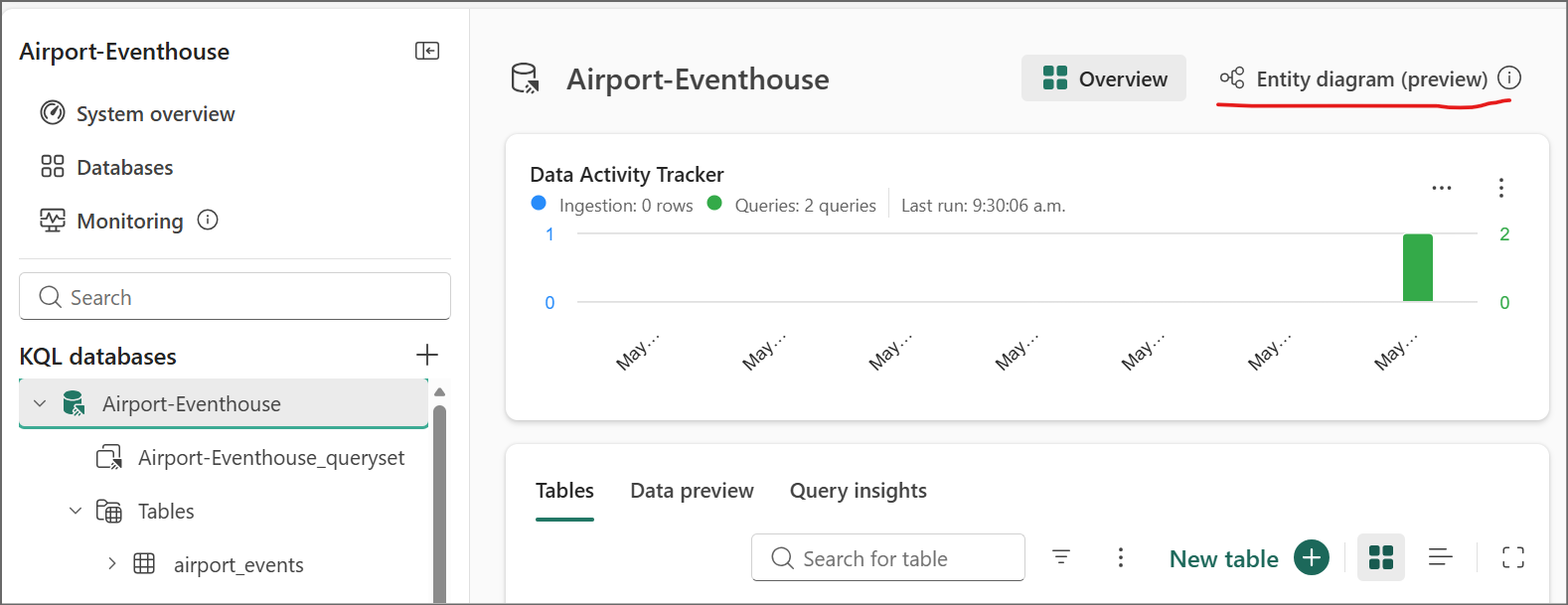
Step 4: Run the Baggage Handling Simulator
Clone the simulator and install dependencies:
git clone https://github.com/calloncampbell/BaggageHandling-TypeB-Simulator.gitcd BaggageHandlingSimulatorpip install -r requirements.txt
Configure the connection string for your Event Hubs namespace or Fabric custom endpoint in config.json (or as environment variables — check the repo README for the exact format).
Run the simulator:
python -m baggage_simulator.cli --verbose --clock-speed 120 --flight-interval-minutes 5 --max-active-flights 5 --eventhub-conn "**********************" --eventhub-name "airport-events-evh"
The --speed multiplier lets you fast-forward simulation time so you don’t have to wait hours for bags to travel through their lifecycle. With --clock-speed 120, a full flight’s baggage cycle completes in minutes.
Within seconds, you should see events flowing into the Eventstream and landing in the Eventhouse Bronze tables.
Step 5: Query the Data
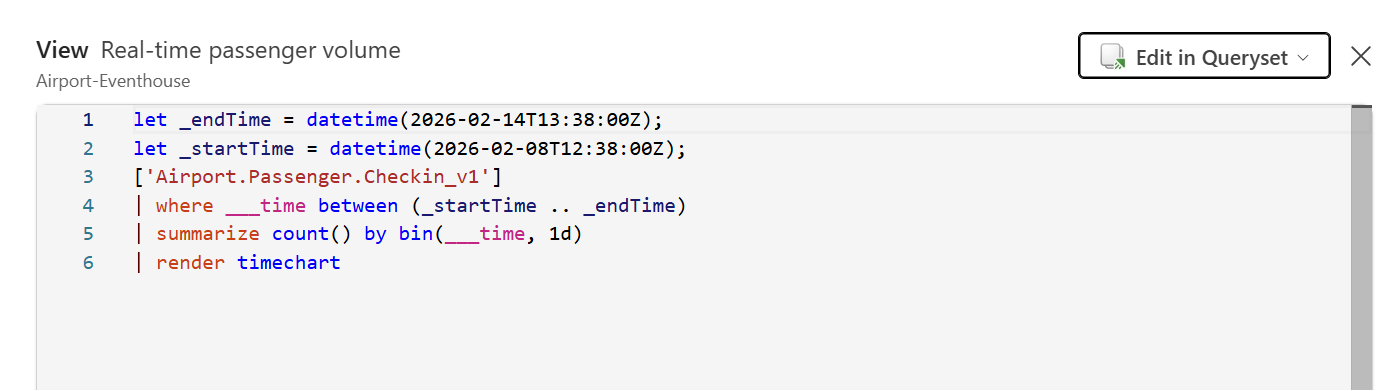
Open a KQL Queryset in your workspace and start exploring. Here are a few queries I find useful:
Track a specific bag end-to-end
BaggageEvents_Silver| where BagTagNumber == "0014567891234"| order by Timestamp asc| project Timestamp, EventCategory, Location, FlightNumber
Find bags that haven’t been delivered (potential mishandles)
BagLatestStatus| where EventCategory != "Delivered" and EventCategory != "Lost"| where Timestamp < ago(2h)| project BagTagNumber, FlightNumber, EventCategory, Location, Timestamp| order by Timestamp asc
Baggage throughput by event type over the last hour
BaggageEventsByHour| where Timestamp > ago(1h)| summarize Total = sum(EventCount) by EventType| order by Total desc| render barchart
Average bag journey time (check-in to delivery) per flight
let CheckIn = BaggageEvents_Silver | where EventCategory == "CheckedIn" | project BagTagNumber, CheckInTime = Timestamp;let Delivered = BaggageEvents_Silver | where EventCategory == "Delivered" | project BagTagNumber, DeliveredTime = Timestamp;CheckIn| join kind=inner Delivered on BagTagNumber| extend JourneyMinutes = datetime_diff('minute', DeliveredTime, CheckInTime)| summarize AvgJourneyMinutes = avg(JourneyMinutes), BagCount = count() by bin(CheckInTime, 1h)| order by CheckInTime desc
Step 6: Build the Real-Time Dashboard
Create a Real-Time Dashboard in your workspace. Add tiles by writing KQL queries directly in the dashboard editor — no separate report tool needed.
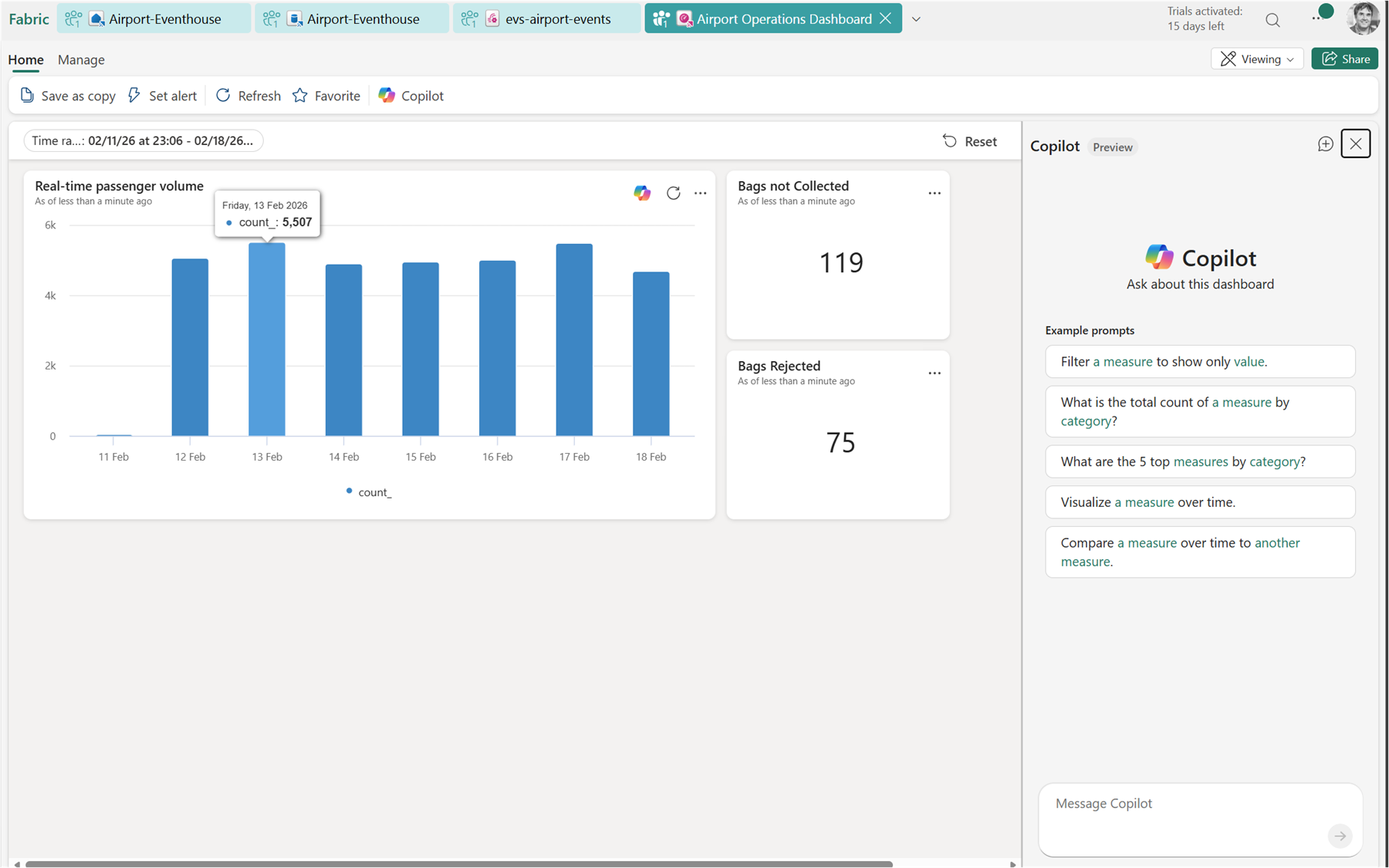
You can always view the query for each of the tiles by clicking on the … menu and then view query:
Useful tiles for this scenario:
- Bags in-flight right now — count of bags with a status other than Delivered or Lost
- Events per minute — a time chart showing ingestion rate
- Lost or rejected bags — a table filtered to
EventCategory in ("Lost", "Rejected") - Baggage throughput by hour — bar or area chart of event volume over time
Set the dashboard auto-refresh to 30 seconds for a live operations feel.
Step 7: Set Up an Activator Alert
Activator is Fabric’s alerting engine, and this is where things get genuinely useful. You can define a rule that watches a KQL query result and triggers an action when a condition is met.
From the Real-Time Dashboard, click Set alert on the “Lost or rejected bags” tile. Configure:
- Condition: row count > 0
- Action: send an email, Teams message, or trigger a Power Automate flow
- Check frequency: every 5 minutes
You can also create Activator items directly from the Eventhouse using Data Activator and write your own detection query — useful for more complex conditions like “bag hasn’t progressed in 45 minutes”:
BagLatestStatus| where EventCategory !in ("Delivered", "Lost")| where Timestamp < ago(45m)
Putting It All Together
Here’s the full flow end-to-end:
- Simulator generates CloudEvents and publishes to Event Hubs / Eventstream endpoint
- Eventstream ingests, routes by event type, and writes to Bronze tables in Eventhouse
- Update Policies automatically promote Bronze → Silver on ingest
- Materialized Views continuously aggregate Silver → Gold
- KQL Querysets power ad-hoc investigation
- Real-Time Dashboard shows live operations at a glance
- Activator fires alerts when something goes wrong
The whole pipeline is serverless from the Eventstream inward — there’s no infrastructure to manage, no Spark jobs to schedule, and no orchestration to babysit.
That’s what I find most impressive about Fabric RTI for this kind of scenario. The time from “event published” to “insight on a dashboard with an alert configured” is measured in minutes, not weeks.
Enjoy!
References
- Microsoft Fabric Real-Time Intelligence — Official documentation and getting started resources
- Eventhouse overview – Microsoft Fabric — KQL database engine in Fabric RTI
- Eventstream overview – Microsoft Fabric — Ingestion and routing for real-time data
- Update Policies in Kusto / Fabric — Automatic Bronze-to-Silver transformation on ingest
- Materialized Views in Kusto / Fabric — Pre-aggregated Gold layer queries
- Data Activator overview – Microsoft Fabric — Alerting and automation engine
- Baggage Handling Simulator by Clemens Vasters — Python CLI for simulating airport baggage events as CloudEvents
- https://github.com/calloncampbell/BaggageHandling-TypeB-Simulator — My fork and changes for Type-B Messages
- IATA Resolution 753 – Baggage Tracking — IATA’s mandate for end-to-end baggage tracking
Bringing Real‑Time Intelligence to Airport Data Streams (Type-B Messages) – Part 1
If you’ve ever wondered what happens to your bag after you drop it off at the check-in counter, you’re not alone. There’s an entire world of events firing beneath the surface of every airport, and it turns out it makes for a pretty compelling real-time data scenario.
I recently put together a use case walkthrough on Bringing Real-Time Intelligence to Airport Data Streams using Microsoft Fabric. In this post, I want to break down the architecture, explain the data model, and show how you can build a real-time observability pipeline over something as relatable as baggage tracking.
Why Airports?
Airports are a great analogy for event-driven systems because every action generates a traceable event:
- You book a flight → event
- You check in → event
- You drop off your bag → event
And that bag doesn’t just teleport to the carousel. It travels through a complex network of baggage belts, ramps, weigh stations, scanners, and machinery. It gets loaded onto the plane, unloaded at the destination, sent through customs (maybe), and eventually delivered to the baggage belt — or it gets lost.
Every step is a state change. Every state change is an opportunity to capture data and act on it in real time.
The Event Model
For this use case, I modelled three categories of events published to the stream:
Baggage Events
Airport.Baggage.CheckedInAirport.Baggage.ScreenedAirport.Baggage.InspectedAirport.Baggage.RejectedAirport.Baggage.LoadedAirport.Baggage.UnloadedAirport.Baggage.CustomsClearedAirport.Baggage.WithheldAirport.Baggage.ArrivedAtBeltAirport.Baggage.DeliveredAirport.Baggage.Lost
Flight Operational Events
Airport.Flight.ClosedAirport.Flight.DepartedAirport.Flight.Arrived
Passenger Events
Airport.Passenger.CheckedIn
This structure follows a clean domain-driven naming convention that maps naturally to a topic-per-domain strategy in Event Hubs or Fabric Eventstream.
Real Airports Use Type-B Messages
In the real world, airports and airlines don’t talk to each other over REST APIs or CloudEvents — they use Aviation Type-B messages, a fixed-format ASCII text messaging standard that’s been in use since the 1960s. These messages are transmitted over dedicated aviation networks operated by SITA (Société Internationale de Télécommunications Aéronautiques) and ARINC (now part of Collins Aerospace), and they remain the backbone of operational messaging across the global aviation industry today.
The key Type-B message types that map directly to this use case are:
| Message | Name | Description |
| BSM | Baggage Source Message | Generated at check-in; carries the bag tag number, passenger details, and routing |
| BTM | Baggage Transfer Message | Used for interline transfer bags moving between airlines |
| BPM | Baggage Processed Message | Confirmation that a bag has been processed at a handling point |
| BUM | Baggage Unload Message | Signals that bags have been removed from an aircraft |
| MVT | Movement Message | Communicates flight departure (AD), arrival (AA), and estimated times (ET) |
| LDM | Load Distribution Message | Describes how cargo and baggage are distributed across the aircraft |
| CPM | Container/Pallet Distribution Message | Details the ULD (Unit Load Device) positioning on the aircraft |
IATA Resolution 753
IATA Resolution 753 mandates that airlines track every bag at a minimum of four key touchpoints:
- Passenger handover at check-in
- Loading onto the aircraft
- Delivery to the transfer area (for connecting flights)
- Return to the passenger at arrival
Resolution 753 exists because lost and mishandled bags cost the industry hundreds of millions of dollars annually, and real-time tracking directly reduces that. It came into effect in 2018 and drove significant investment in baggage scanning infrastructure and data exchange across airlines and ground handlers.
Bridging Type-B to Modern Streaming
Here’s where it gets interesting from a platform perspective. Type-B messages carry all the right information — they’re just locked inside a legacy fixed-format protocol on a private network. The modernization opportunity is to parse and bridge those messages into a modern event stream.
In practice, that means something like:
- A SITA or ARINC Type-B feed gets received by a gateway or middleware layer
- Each message is parsed and mapped to a structured event (e.g., a BSM becomes an
Airport.Baggage.CheckedInCloudEvent) - That event is published to Azure Event Hubs or a Fabric Eventstream endpoint
- From there, the full Fabric RTI pipeline takes over
The Baggage Handling Simulator in this demo effectively plays the role of that gateway — it generates CloudEvents that mirror what you’d produce by parsing a real Type-B feed. If you were building this for production, the simulator would be replaced by a Type-B parser wired up to a live SITA or ARINC connection.
Architecture Overview
Here is an overview of the architecture in Microsoft Fabric Real-Time Intelligence:
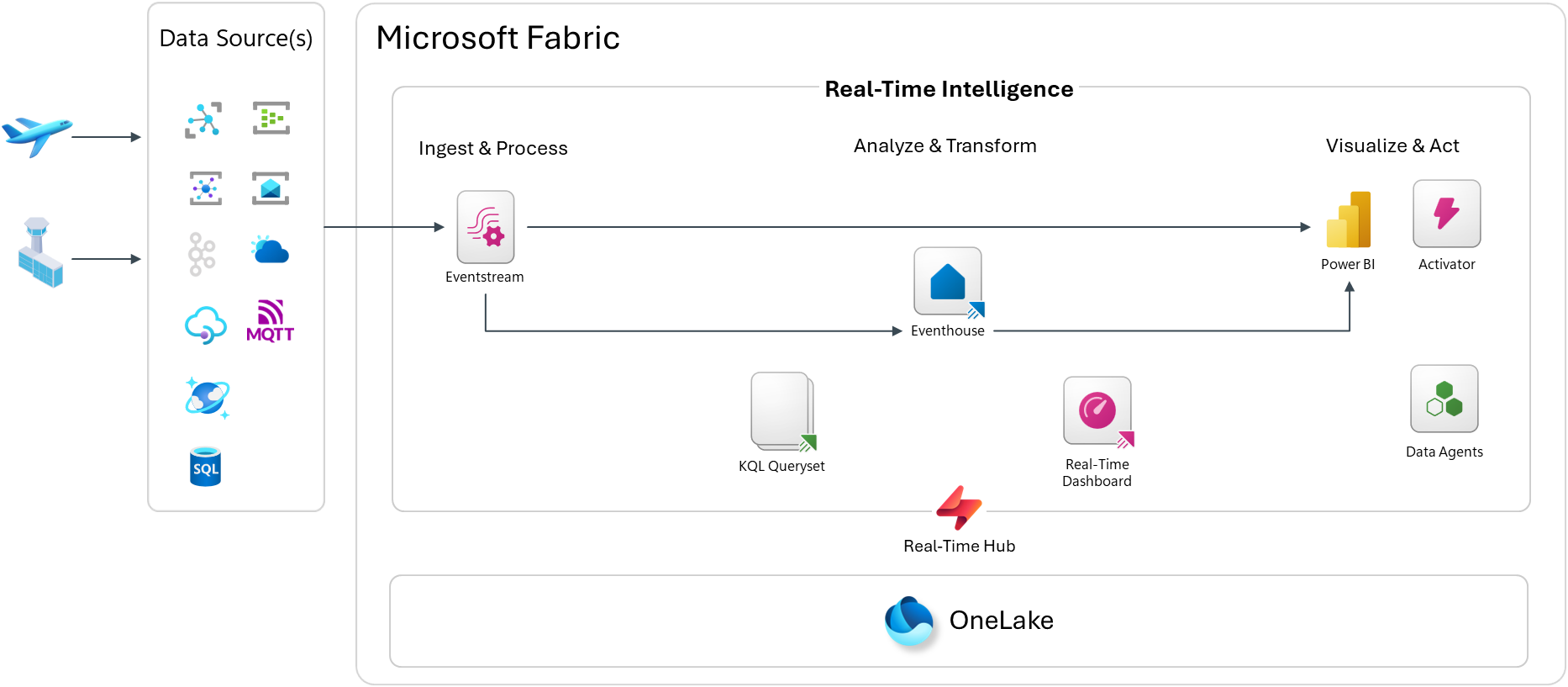
The pipeline follows a standard Ingest → Analyze → Act pattern inside Microsoft Fabric Real-Time Intelligence:
Ingest & Process
Events are published to Azure Event Hubs or directly to a Microsoft Fabric Eventstream endpoint as CloudEvents. The Real-Time Hub acts as the central discovery and governance point for all streaming sources in the workspace.
Eventstream picks up those events and routes them into the Eventhouse — Fabric’s purpose-built KQL database engine optimized for high-throughput, time-series, and log-style workloads.
Inside the Eventhouse, I use a classic Bronze / Silver / Gold medallion layering approach:
- Bronze — raw ingested events, exactly as received
- Silver — cleaned and enriched data via Update Policies (KQL-based transformation rules that fire automatically on ingest)
- Gold — aggregated and pre-computed views via Materialized Views for fast querying
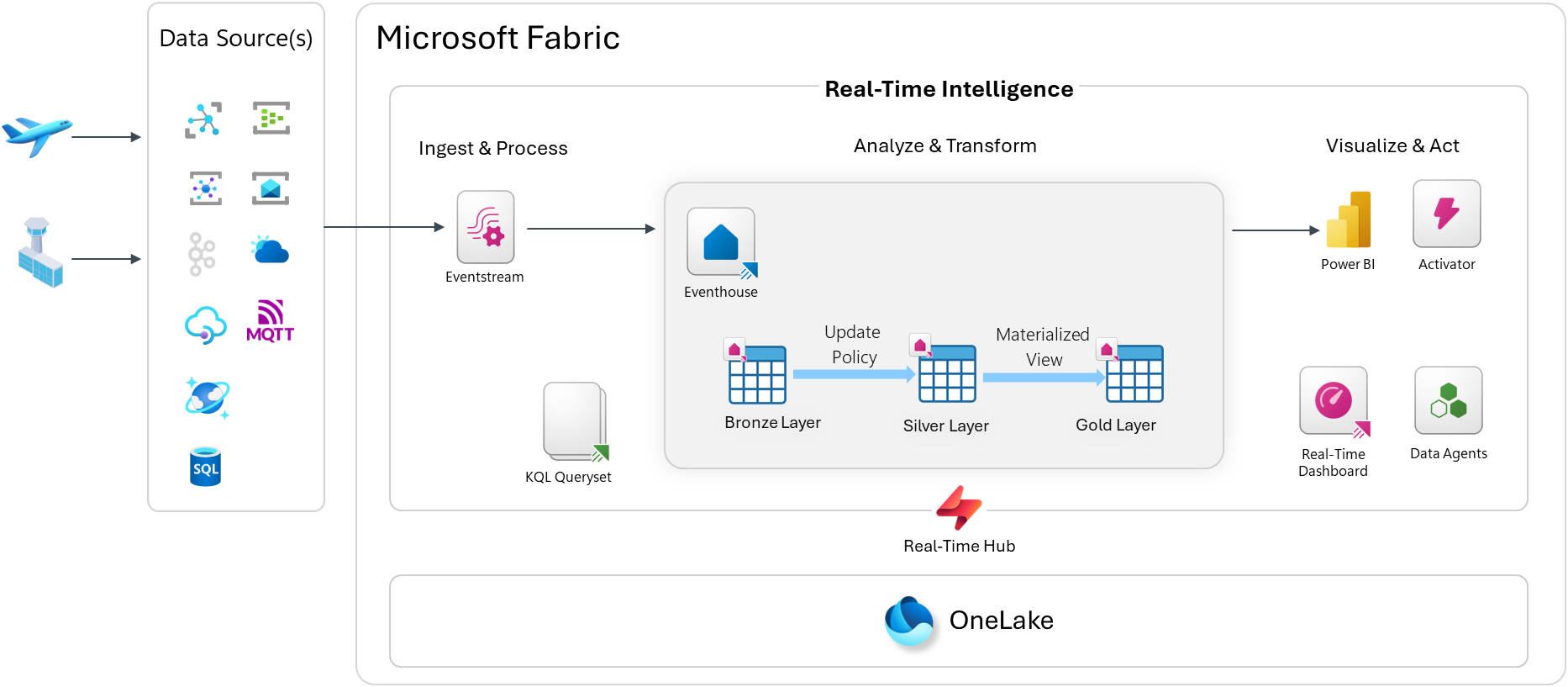
Analyze & Transform
KQL Querysets sit on top of the Eventhouse and let you write ad-hoc and saved queries in Kusto Query Language. KQL is incredibly expressive for time-series data — you can window events, calculate SLAs, detect anomalies, and join across streams with just a few lines.
Visualize & Act
From there, you have a few options:
- Real-Time Dashboard — a native Fabric dashboard that auto-refreshes on a schedule or on data change, built directly from KQL queries
- Power BI — for richer semantic model-based reporting or executive dashboards
- Activator — Fabric’s alerting and automation engine; you can define rules like “if a bag hasn’t moved in 30 minutes, fire an alert”
- Data Agents — AI-powered agents that can answer natural language questions over your KQL data
Data can also land in OneLake, so it’s available for downstream batch analytics and data science workloads. This is not enabled by default, so it’s something you would need to turn on.
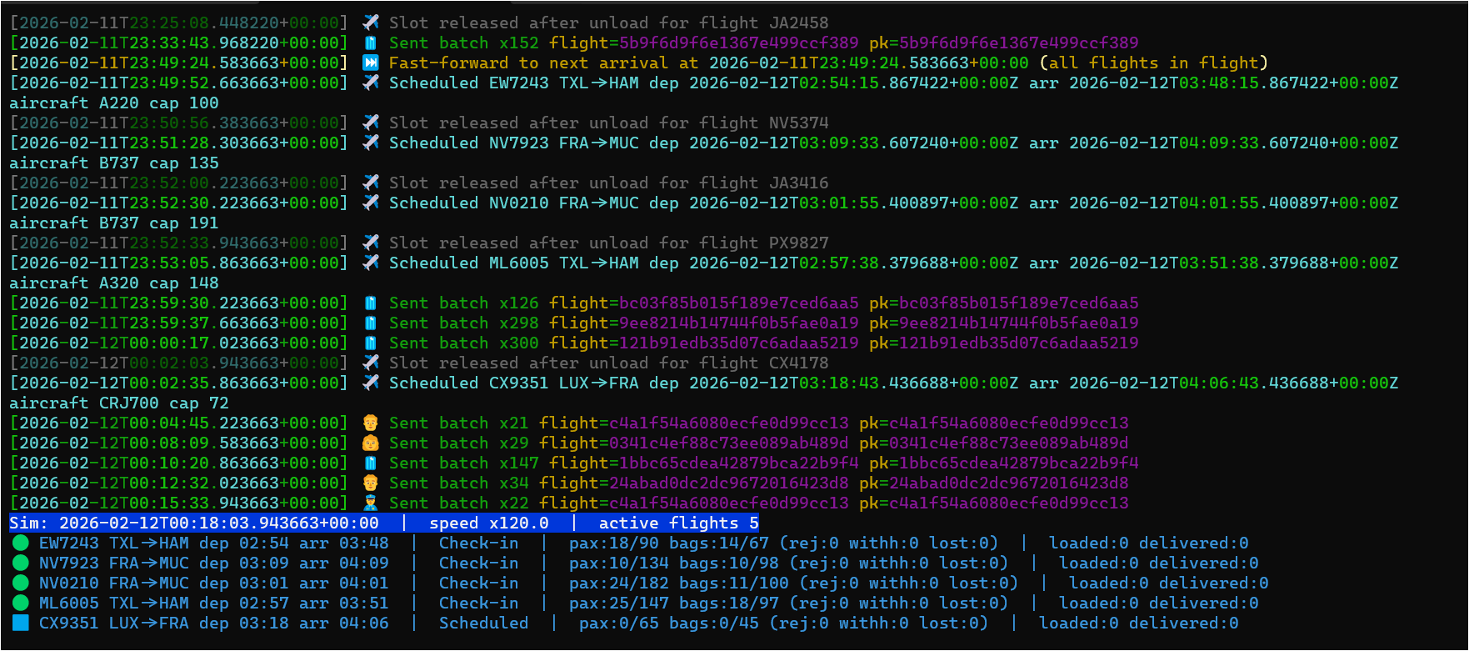
The Baggage Handling Simulator
To drive the demo, I used the Baggage Handling Simulator — a Python CLI built by Clemens Vasters that simulates realistic airport baggage operations. I forked the repository and then adjusted it for Type-B messaging. You can find my fork on GitHub: calloncampbell/BaggageHandling-TypeB-Simulator at feature/type-b-messages
The simulator generates:
- Baggage tracking events (check-in, screening, loading, unloading, delivery)
- Passenger events (check-in, boarding)
- Flight lifecycle events (scheduled, closed, departed, arrived)
Events are published as CloudEvents to either Azure Event Hubs or a Fabric Eventstream endpoint. Flight schedules are also persisted to SQL Server, which gives you a relational anchor to join against your streaming data if needed.
This is a great reference simulator if you want to explore real-time analytics without having to stand up your own IoT or event infrastructure.
Let’s look at the simulator…
Now let’s look at a basic Real-Time Dashboard:
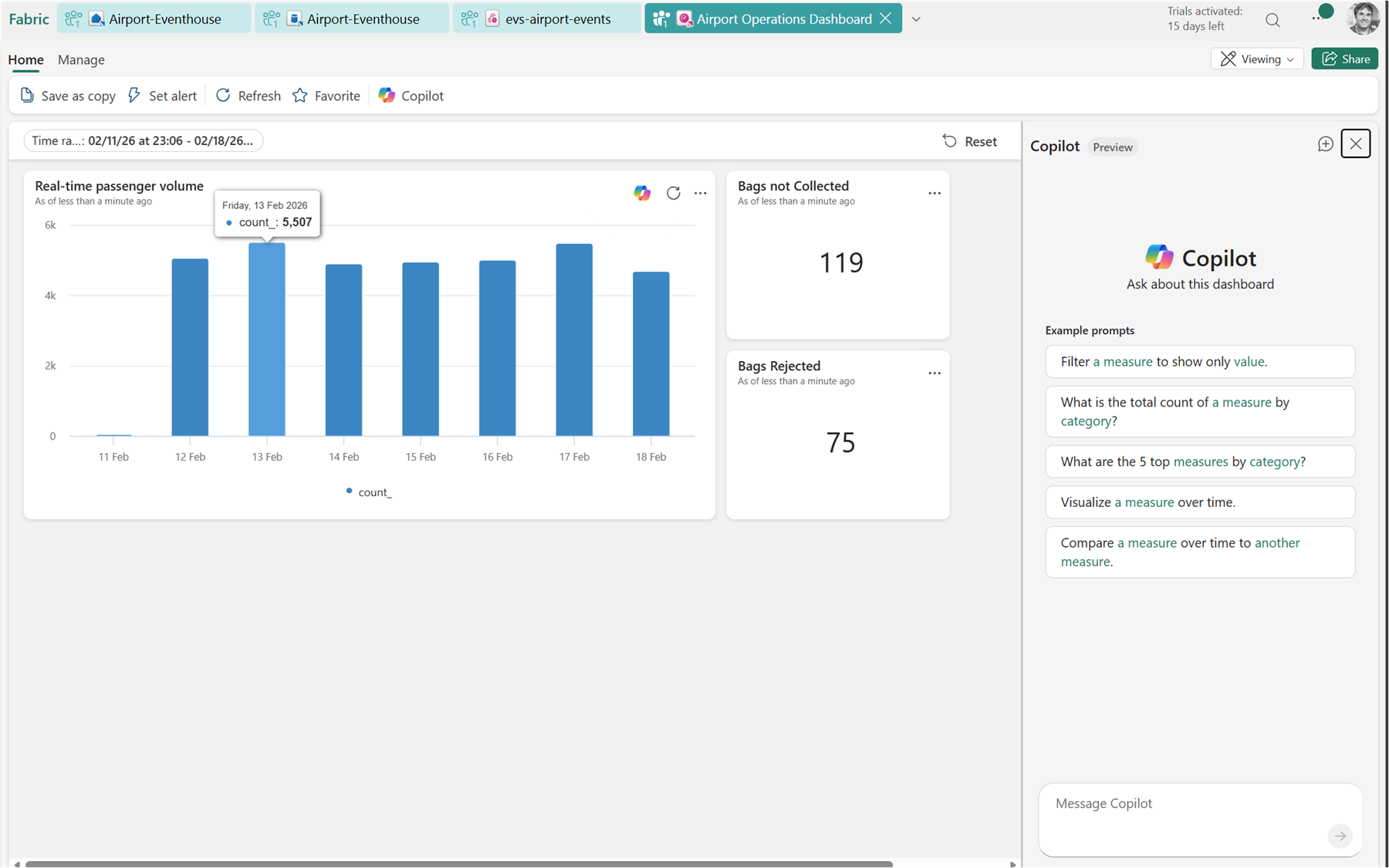
What I Took Away
What I find compelling about this use case is how approachable it is. Most people have been through an airport. Most people have waited anxiously at a baggage belt. That shared experience makes the data model immediately intuitive — and that makes it a great teaching scenario for real-time streaming concepts.
From a Fabric RTI perspective, this use case demonstrates a few things I think are really powerful:
- The medallion pattern works in streaming too. Update Policies and Materialized Views give you that Bronze/Silver/Gold structure without a separate transformation job or orchestration layer.
- KQL is a first-class citizen. It’s not just a query language — it’s the transformation layer, the alerting layer, and the visualization layer.
- Activator closes the loop. Moving from insight to action inside the same platform — without building custom workflows — is genuinely useful.
If you’re interested in exploring Microsoft Fabric Real-Time Intelligence, this airport scenario is a solid and fun way to get started. In Part 2 of this post, I’ll dig into the Fabric Real-Time Intelligence setup.
Enjoy!
References
- Microsoft Fabric Real-Time Intelligence — Official documentation and getting started resources
- Next Real-Time Intelligence Adoption — Adoption guidance and resources
- aka.ms/realtimeintelligence
- aka.ms/nextrtiad
- Baggage Handling Simulator by Clemens Vasters — Python CLI for simulating airport baggage events as CloudEvents
- CloudEvents Specification — Vendor-neutral event format used by the simulator
- IATA Resolution 753 – Baggage Tracking — IATA’s mandate for end-to-end baggage tracking at four key touchpoints
- SITA – Aviation Messaging — Type-B messaging infrastructure for the aviation industry
- Here’s what happens to checked luggage at Pearson Airport | Pearson Airport
Centralizing NuGet Package Versions with Central Package Management
In my Running and Building Azure Functions with Modern .NET talk this week at the Mississauga .NET User Group, one of the topics that consistently gets a reaction from the audience is Central Package Management (CPM). Once I show people what it does, the reaction is almost always the same: “I didn’t know this existed — I need to go add this to all my solutions.”
This post is the written companion to that section of the talk. If you’ve ever dealt with the pain of keeping NuGet package versions in sync across a large solution, CPM is going to be immediately relevant to you.
What is Central Package Management?
Central Package Management is a built-in .NET feature that lets you define all NuGet package versions in a single place — a Directory.Packages.props file at the solution root — rather than scattering Version attributes across individual .csproj files.
Here’s a simple example of what that file looks like:
<Project> <PropertyGroup> <ManagePackageVersionsCentrally>true</ManagePackageVersionsCentrally> </PropertyGroup> <ItemGroup> <PackageVersion Include="Microsoft.Azure.Functions.Worker" Version="2.0.0" /> <PackageVersion Include="Microsoft.Azure.Functions.Worker.Extensions.Http" Version="3.3.0" /> <PackageVersion Include="Newtonsoft.Json" Version="13.0.3" /> </ItemGroup></Project>
And in your individual .csproj files, you simply reference the package without a version:
<ItemGroup> <PackageReference Include="Microsoft.Azure.Functions.Worker" /> <PackageReference Include="Newtonsoft.Json" /></ItemGroup>
The version is automatically resolved from the central file. Clean, simple, and immediately obvious what version you’re on when you look at the central file.
Why This Matters
In a solution with many projects, keeping package versions in sync manually is error-prone. You end up with Project A on Newtonsoft.Json 13.0.1 and Project B on 13.0.3 without anyone really noticing until a subtle runtime difference bites you. CPM solves this by making version drift impossible — there’s one place to look and one place to change.
Benefits at a glance:
- Single source of truth for all package versions in the solution
- Eliminates version drift across projects
- Cleaner
.csprojfiles — no version attributes cluttering your package references - Supports both direct and transitive dependency version control
Manually Migrate an Existing Solution to CPM
If you already have a solution with a bunch of projects, migrating to CPM is straightforward but can be tedious to do by hand across many .csproj files. Here’s the approach:
Step 1: Create Directory.Packages.props
At the root of your solution, create a Directory.Packages.props file with ManagePackageVersionsCentrally set to true and consolidate all your package versions as <PackageVersion> entries:
<Project> <PropertyGroup> <ManagePackageVersionsCentrally>true</ManagePackageVersionsCentrally> </PropertyGroup> <ItemGroup> <PackageVersion Include="PackageName" Version="x.y.z" /> <!-- add all packages here --> </ItemGroup></Project>
Step 2: Remove Versions from Project Files
Strip the Version attribute from every <PackageReference> in your .csproj files. If you have many projects, do this with the CentralisedPackageConverter CLI tool (covered below) — don’t do it by hand.
Step 3: Validate and Build
Build your solution and confirm everything resolves correctly. Pay attention to any packages that may have conflicting versions across projects — those will need a conscious decision about which version to standardize on.
This is great, but there must be a better way. Let’s take a look at a community tool that automates this process.
Using the CentralisedPackageConverter CLI Tool
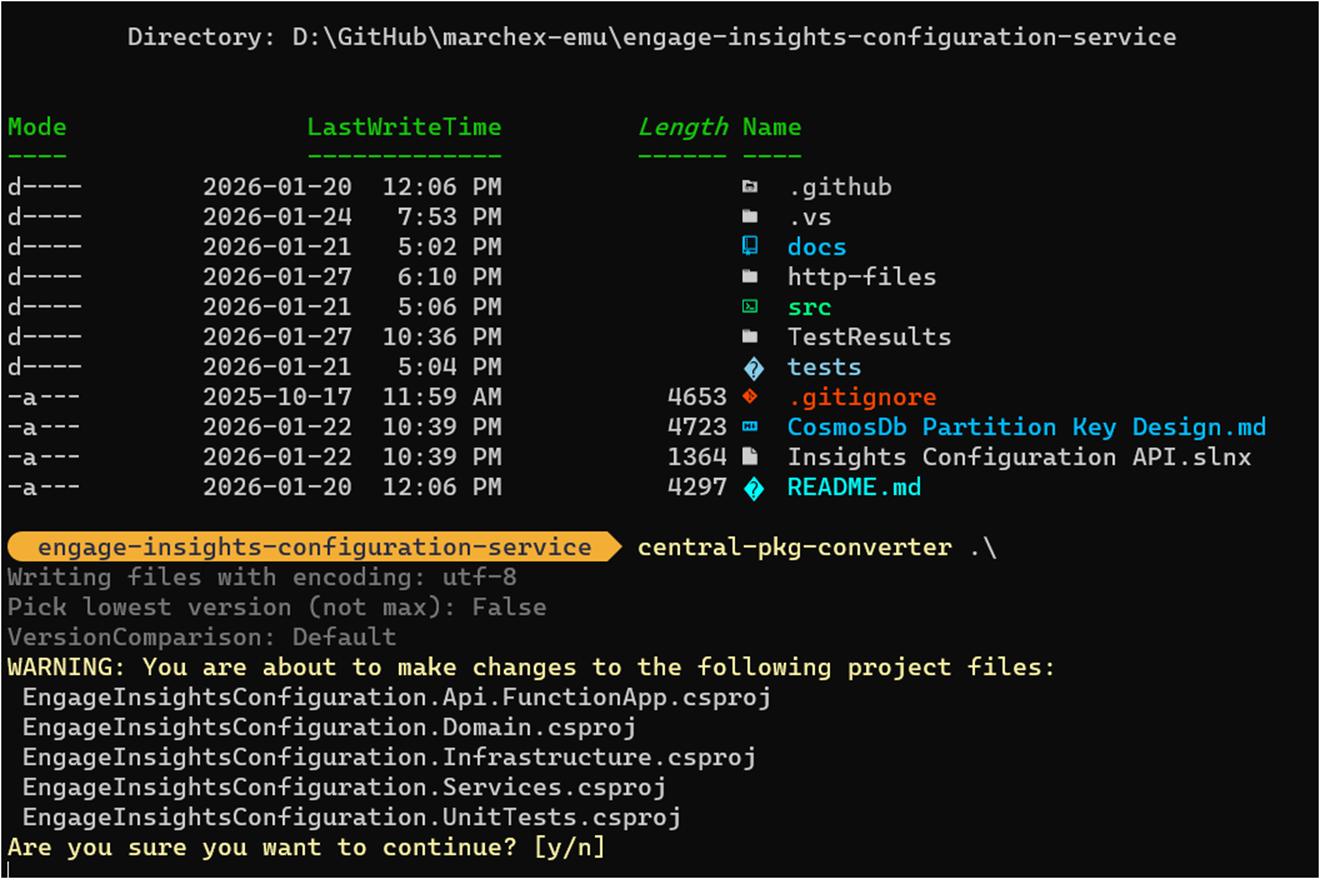
The best way to handle the migration for an existing solution is the CentralisedPackageConverter CLI tool, which automates the tedious parts:
# Install the tool globallydotnet tool install CentralisedPackageConverter --global# Run the conversion against your solution foldercentral-pkg-converter /path/to/your/solution/folder
The tool will:
- Scan all
.csprojfiles in the solution - Generate a
Directory.Packages.propswith all discovered versions - Remove version attributes from individual project files
I highly recommend using this over a manual migration. It’s fast and reduces the chance of missing something.
Let’s try this out.
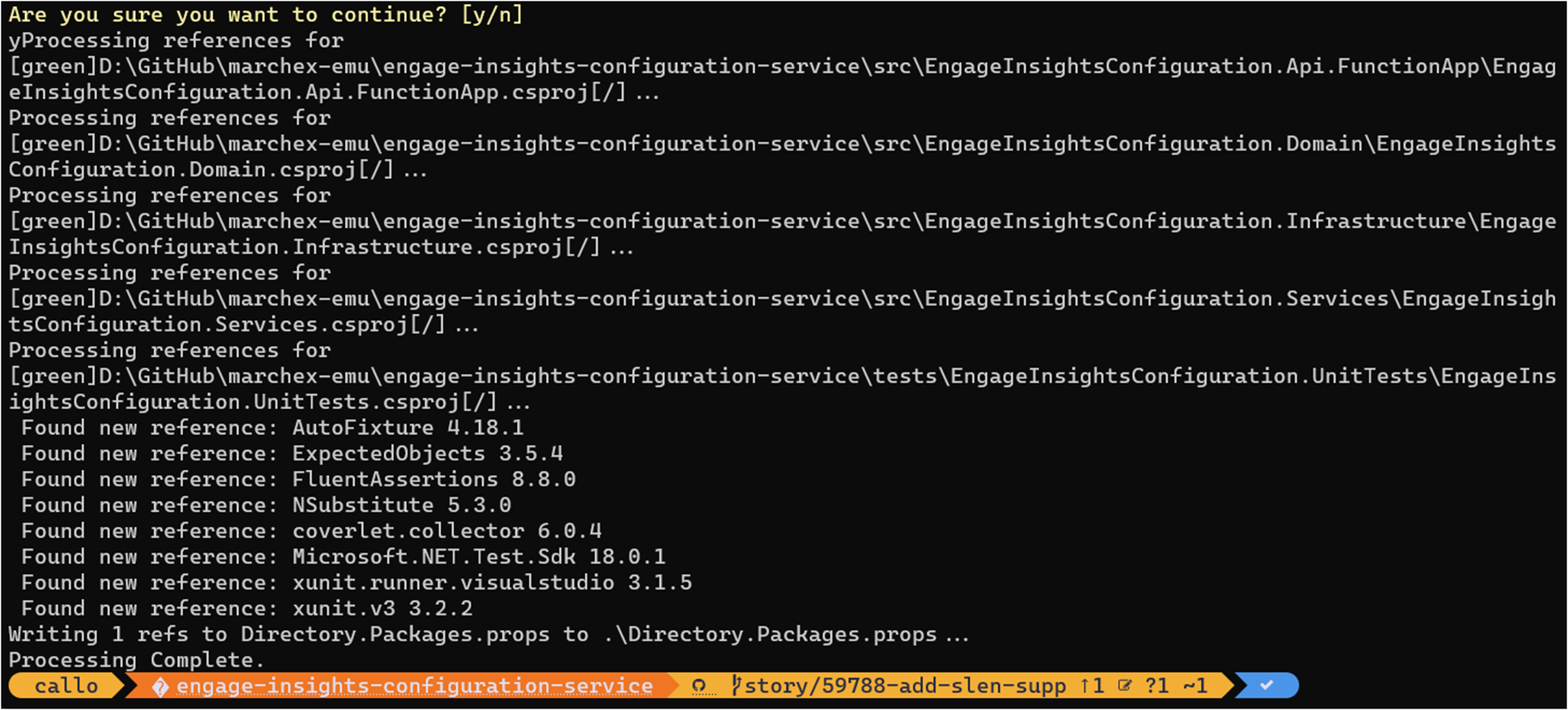
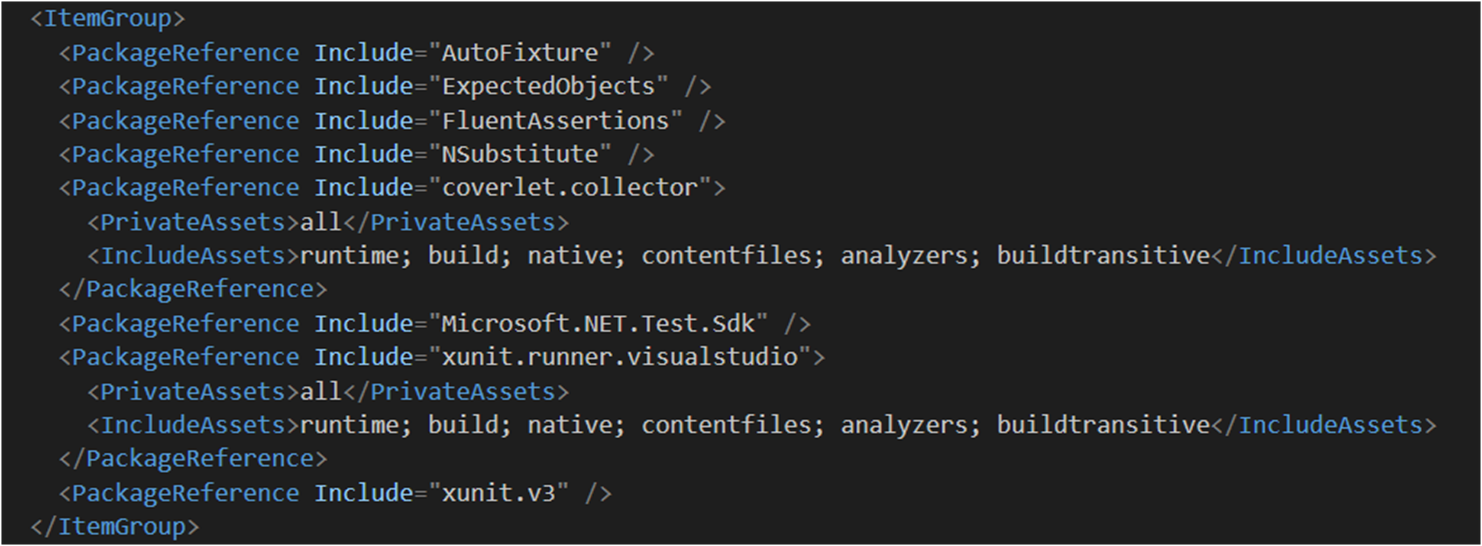
We now have a Directory.Packages.props with all discovered versions:
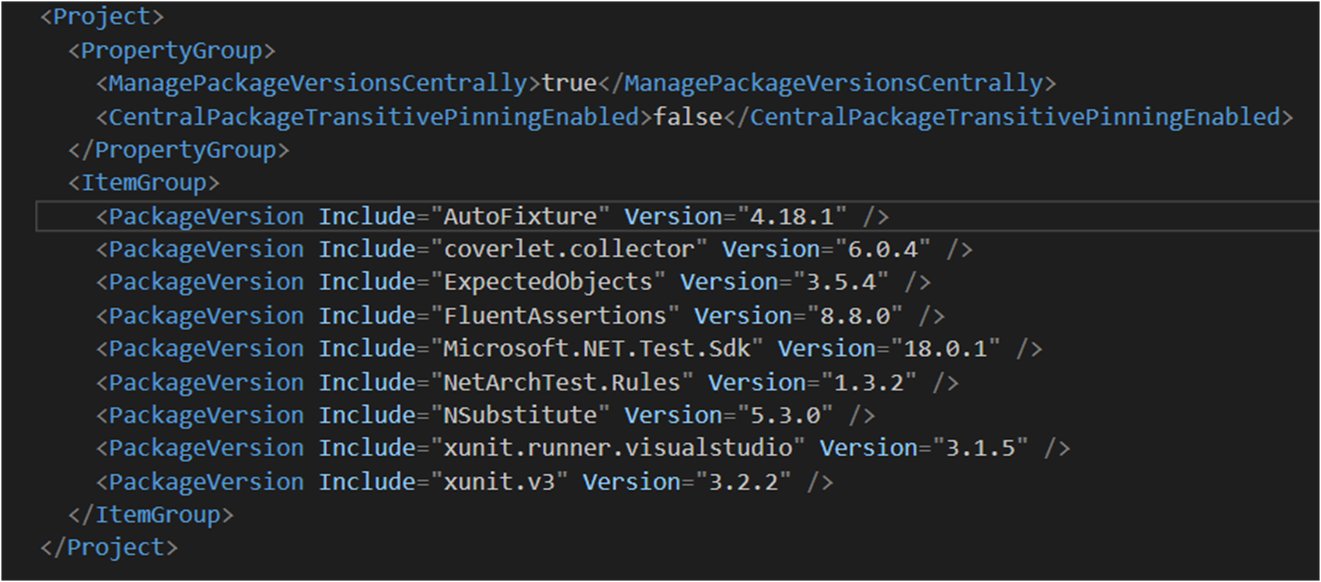
And if we look in our project files, the versions are removed:
Advanced Features
Once you’re on CPM, there are a few additional capabilities worth knowing about.
Overriding Versions per Project
There are situations where a specific project needs a different version of a package than the rest of the solution — say, a legacy integration that can’t move to the latest version yet. CPM handles this with VersionOverride in the individual project file:
<PackageReference Include="SomePackage" VersionOverride="1.2.3" />
Use this sparingly. Its presence in a project file is a signal that something needs attention.
Different Versions per Target Framework
If you have a multi-targeted project, you can conditionally apply different versions by target framework using standard MSBuild conditions within Directory.Packages.props:
<PackageVersion Include="SomePackage" Version="2.0.0" Condition="'$(TargetFramework)' == 'net10.0'" /><PackageVersion Include="SomePackage" Version="1.5.0" Condition="'$(TargetFramework)' == 'net8.0'" />
Transitive Pinning
This one quietly solves a very real problem. Version drift caused by transitive dependencies — packages your packages depend on — is easy to miss and can cause subtle compatibility issues. CPM supports pinning transitive dependencies centrally, so you stay in control of the full dependency graph, not just the packages you reference directly.
Summary
Central Package Management is one of those features that makes you wonder how you managed without it once you adopt it. If you’re running a multi-project .NET solution, this is a straightforward improvement with immediate payoff — consistent package versions, cleaner project files, and a single place to make dependency updates.
Enjoy!
References
- Central Package Management — NuGet documentation — Official docs and full feature reference
- CentralisedPackageConverter on NuGet — CLI tool for automated migration
- Directory.Packages.props reference — Enabling and configuring CPM
- Mississauga .NET User Group — Meetup group where this was presented
The New .slnx Solution File Format — A Better Way to Manage Visual Studio Solutions
In my Running and Building Azure Functions with Modern .NET talk this week at the Mississauga .NET User Group, I closed out the .NET tooling section with a quick look at the new .slnx solution file format. It’s one of those changes that doesn’t get a lot of attention but makes day-to-day .NET development noticeably more pleasant — especially if you’ve ever dealt with a gnarly merge conflict in a .sln file.
This post walks through what .slnx is, why it’s better than the traditional .sln format, and how to migrate.
What’s Wrong with .sln?
If you’ve worked with Visual Studio solutions for any length of time, you’ve almost certainly encountered the pain points with .sln files. They’ve been around since the early 2000s and they work — but they come with a set of frustrations that have never really been addressed:
- They’re nearly unreadable — the format uses GUIDs and magic identifiers that aren’t intuitive at all
- Merging is painful — a
.slnfile being touched by two developers at the same time is a merge conflict waiting to happen - Tooling struggles with them — custom scripts or CI tooling that needs to parse a
.slnfile often resorts to fragile string manipulation
Here’s a snippet of a traditional .sln to illustrate:
Project("{FAE04EC0-301F-11D3-BF4B-00C04F79EFBC}") = "MyFunctions", "src\MyFunctions\MyFunctions.csproj", "{A1B2C3D4-E5F6-1234-ABCD-EF0123456789}"EndProjectGlobal GlobalSection(SolutionConfigurationPlatforms) = preSolution Debug|Any CPU = Debug|Any CPU Release|Any CPU = Release|Any CPU EndGlobalSectionEndGlobal
Not exactly something you want to review in a pull request.
Introducing .slnx
The .slnx format is a new, XML-based solution file format introduced in the .NET 9.0.200 SDK. It addresses all of the above problems:
<Solution> <Project Path="src/MyFunctions/MyFunctions.csproj" /> <Project Path="src/MyFunctions.Tests/MyFunctions.Tests.csproj" /></Solution>
That’s it. No GUIDs. No magic identifiers. No indecipherable global sections. Just a clean XML file that clearly describes what’s in the solution.
Why It’s Better
Better readability — the XML structure is immediately understandable. Any developer can open a .slnx file and know exactly what’s in the solution without reverse-engineering the format.
Simplified merging — because it’s XML with simple, meaningful elements rather than a blob of GUIDs and platform strings, merge conflicts in .slnx files are much easier to resolve. In most cases, merging two developers’ changes to the solution file becomes a trivial diff.
Easier parsing — if you write build scripts, CI automation, or any tooling that needs to know what projects are in a solution, parsing a .slnx file is now just standard XML parsing. Reliable and straightforward.
Converting from .sln to .slnx
The .NET CLI makes the migration trivially easy. From your solution folder, run:
dotnet sln migrate
From Visual Studio 2022
Go to File and save your solution file as…and select the XML Solution File format.
Before You Migrate
A few things to check before running the migration:
Commit your existing .sln file to source control before converting — gives you a clean rollback point if anything looks off.
Make sure your entire team is on a compatible toolchain — .NET SDK 9.0.200 or later, and a recent version of Visual Studio 2022 or Visual Studio 2026. Anyone still on an older setup won’t be able to open the solution until they update.
If you have CI/CD pipelines that parse or manipulate the .sln file directly (not uncommon in larger teams), update those to handle .slnx before you switch over.
Should You Migrate?
My honest take is yes, especially for new solutions. For existing solutions, there’s no urgency — your .sln files aren’t going anywhere — but if you’re already bumping into merge conflict pain or your solution file is getting unwieldy, the migration is trivially easy, and the payoff is immediate.
For new projects, I’d start with .slnx from day one. In fact if you’ve migrated over to Visual Studio 2026 it’s now the default options. It’s the better format, it’s supported by all current tooling, and you’ll thank yourself later.
Summary
The .slnx solution file format is a small change with a noticeably positive impact on day-to-day .NET development. XML-based, human-readable, merge-friendly, and trivially easy to adopt — there’s very little reason not to switch. Combined with Central Package Management and the new Azure Functions FunctionsApplication builder, these three improvements together represent a meaningfully cleaner modern .NET development experience.
Enjoy!
References
dotnet slnCLI reference — Includes themigratecommand documentation- .NET SDK 9.0.200 release notes — Where
.slnxwas introduced - What’s new in Visual Studio 2022 — Visual Studio support for
.slnx - Mississauga .NET User Group — Meetup group where this was presented
Upgrading Azure Functions to .NET 10 — What You Need to Know

In my Running and Building Azure Functions with Modern .NET talk last week at the Mississauga .NET User Group, the session covered a handful of topics that I think every .NET developer building on Azure Functions should know about — upgrading to .NET 10, centralizing package management, and the new solution file format. This is the first in a short series of posts walking through each of those topics. Let’s start with .NET 10 support in Azure Functions and what’s new.
.NET 10 is Now Supported in Azure Functions
Azure Functions now supports .NET 10 on runtime version 4.x, and it’s a big deal for anyone who cares about building modern, long-lived serverless applications. .NET 10 support runs until November 14, 2028, so you’ve got a solid runway once you’re on it.
A few things to keep in mind before you start your upgrade:
- Only the isolated worker model supports .NET 10. The in-process model is not receiving a .NET 10 update and reaches end of support on November 10, 2026. If you haven’t started migrating off in-process, that date should be your motivation to get moving.
- .NET 10 runs on Functions 4.x across most hosting plans. The one exception is Linux Consumption, which will not receive .NET 10 support. If that’s your current plan, Flex Consumption is the migration target.
- The base container images have shifted from Debian to Ubuntu with .NET 10. If you have custom container builds, verify this against the official release notes before upgrading.
Minimum package versions required for .NET 10:
| Package | Minimum Version |
| Microsoft.Azure.Functions.Worker | 2.50.0 |
| Microsoft.Azure.Functions.Worker.Sdk | 2.0.5 |
Make sure you’re on at least these versions or the runtime will not load correctly.
Before You Upgrade — Quick Checklist
- [ ] Confirm you’re on the isolated worker model (not in-process)
- [ ] Confirm your hosting plan supports .NET 10 (see above)
- [ ] Update
Microsoft.Azure.Functions.WorkerandMicrosoft.Azure.Functions.Worker.Sdkto the minimum versions above - [ ] If migrating from in-process: swap
Microsoft.NET.Sdk.FunctionsforMicrosoft.Azure.Functions.Worker.Sdk, and replaceMicrosoft.Azure.WebJobs.*packages withMicrosoft.Azure.Functions.Worker.Extensions.*equivalents - [ ] Verify your HTTP integration choice (see builder pattern section below)
- [ ] Test locally with Azure Functions Core Tools v4
The New FunctionsApplication Builder Pattern
The biggest developer-facing change in .NET 10 (and technically available since .NET 8 with certain configurations) is the switch to the FunctionsApplication.CreateBuilder pattern. If you’ve been building with the older HostBuilder approach, this will feel familiar but noticeably cleaner.
Here’s what the old pattern looked like:
var host = new HostBuilder() .ConfigureFunctionsWorkerDefaults() .ConfigureServices(services => { services.AddSingleton<IMyService, MyService>(); }) .Build();await host.RunAsync();
And here’s the new pattern:
var builder = FunctionsApplication.CreateBuilder(args);builder.ConfigureFunctionsWebApplication();builder.Services.AddSingleton<IMyService, MyService>();await builder.Build().RunAsync();
Note: ConfigureFunctionsWebApplication() is for functions apps that use ASP.NET Core HTTP integration — it wires up the ASP.NET Core middleware pipeline. If your app is non-HTTP (queue triggers, timers, Service Bus, etc.) and you don’t need that integration, use ConfigureFunctionsWorkerDefaults() instead. Most starter templates will choose the right one, but it’s worth knowing what each does.
It’s a small surface area change but the intent is meaningful. Let me walk through why this matters.
Alignment with ASP.NET Core
ASP.NET Core has used WebApplication.CreateBuilder(args) since .NET 6. Azure Functions now mirrors this with FunctionsApplication.CreateBuilder(args). This consistency across .NET workloads is genuinely helpful — developers who work on both web APIs and Azure Functions no longer need to context-switch between two different initialization mental models.
Direct Access to the Services Collection
The old pattern required you to register services inside a ConfigureServices callback, which added an extra layer of nesting. With the new pattern, you access builder.Services directly — just like you would in an ASP.NET Core Program.cs. Cleaner, more readable, and easier to reason about.
Modern .NET Host Builder Infrastructure
Under the hood, the new pattern is built on HostApplicationBuilder, the modern hosting infrastructure introduced in .NET 6+. This brings with it better performance, improved configuration ordering, and enhanced hosting abstractions. It’s part of Microsoft’s broader effort to unify .NET across web apps, Azure Functions, Worker Services, and other application types — and honestly, it’s a move in the right direction.
I have a sample application over on my GitHub: calloncampbell/FunctionAppMigration at demo3-migrated-net10
What About Flex Consumption?
If you’re migrating off Linux Consumption — or just evaluating where to run modern Azure Functions — Flex Consumption is where the platform is headed and worth understanding alongside your .NET 10 upgrade.
Flex Consumption is a Linux-based hosting plan built on a new backend internally called Legion. It keeps the serverless pay-for-what-you-use billing model you’re used to, but it adds a lot more control:
- Scale to hundreds of instances in under a minute
- Up to 1,000 scale-out instances (note: scale-out instances and per-instance concurrency are separate concepts — you configure concurrency independently)
- Configurable per-instance concurrency
- VNET integration with scale-to-zero still supported
- Always-ready instances that reduce cold-start latency (optional; default is 0, so you pay only when you need them)
- Multiple memory size options
- Availability Zones support
If you’re building anything serious on Azure Functions right now, Flex Consumption paired with .NET 10 is where I’d be pointing you.
Summary
.NET 10 support in Azure Functions is a worthwhile upgrade. The migration from in-process to isolated worker model is no longer optional — with end of support coming November 2026 you need a plan. And once you’re on isolated worker with .NET 10, the new FunctionsApplication builder pattern makes initialization cleaner and more aligned with the rest of the .NET ecosystem. Pair that with a move to Flex Consumption and you’ve got a solid, modern foundation for your serverless workloads.
In the next posts in this series I’ll cover Central Package Management and the new SLNX solution file format — two more improvements that make the .NET developer experience noticeably better.
Enjoy!
References
- Azure Functions isolated worker model guide — Official docs for the isolated worker model
- What’s new in .NET 10 — Overview of .NET 10 features
- Migrate from in-process to isolated worker model — Step-by-step migration guide
- Azure Functions Flex Consumption GA announcement — General availability blog post
- Flex Consumption samples
- Try .NET 10 today — Download and get started
C# on Microcontrollers? Embedded Systems with .NET nanoFramework will show you how.
José Simões’ new book, Embedded Systems with nanoFramework, is a milestone for anyone who’s ever wanted to bring the power and comfort of C# into the world of microcontrollers. What I love about this work is how it breaks down the traditional barriers of embedded development—complex toolchains, steep learning curves, and hardware‑specific code—and replaces them with a modern, flexible, developer‑friendly approach.
At its core, the book shows how the .NET nanoFramework lets you build IoT and embedded solutions quickly, cleanly, and affordably. You can prototype in hours, adapt to customer needs on the fly, and move across ESP32.
José brings deep experience as the founder of the nanoFramework and a multi‑year Microsoft MVP, and it shows.
For a deeper dive on the book, checkout Sander’s post where he goes more in depth.
Want to learn more?
Learn about the .NET nanoFramework from the best!
You can buy this book from several online bookstores. You can get it from Amazon here.
Enjoy!
What’s New with Azure IoT Operations – Ignite 2025 Announcements
Last week, on December 4th, I presented at the Metro Toronto Azure Community meetup, discussing Microsoft’s announcements for Azure IoT Operations (AIO) at Ignite 2025. It was a fantastic evening — fellow MVPs Cliff Agius, Sander Van De Velde, Pete Gallagher, and Jose Simoes also took the stage with their own sessions on various Azure IoT topics.
IoT is a hobby interest of mine, so I genuinely enjoy keeping an eye on what’s happening in this space. When the Ignite announcements dropped, I was already deep in the details, which made putting the session together a lot of fun. This post is the written companion to that talk — a handy reference if you attended and want to revisit anything, or a full walkthrough if you missed it.
What is Azure IoT Operations?
If you’re new to Azure IoT Operations, let me give you a quick grounding before we jump into the announcements. AIO is AI-ready infrastructure for intelligent, adaptive operations. I describe it as more than a data pipeline — it serves as the foundation for integrating AI into the physical world. It enables systems that can perceive, reason, and act, which is precisely what modern industrial environments need to drive real operational efficiency.
What makes AIO stand out:
- Built on Arc-enabled Kubernetes, ensuring a consistent management plane whether you’re on-premises, at the edge, or in the cloud
- Unifies OT and IT data across distributed sites — effectively breaking down those frustrating silos between operational and business systems
- Provides a repeatable, scalable platform that you can deploy across sites without starting from scratch each time
- Extends familiar Azure management concepts to physical locations, which is significant for teams that are already acquainted with Azure.
Ignite 2025 Announcements at a Glance
The Ignite 2025 announcements for Azure IoT Operations are centered on three significant themes:
- New edge-to-cloud orchestration capabilities
- Tighter integration with Microsoft Fabric and Foundry
- AI-driven observability and governance tools
Let’s explore each of the specific features that were announced.
Wasm-Powered Data Graphs
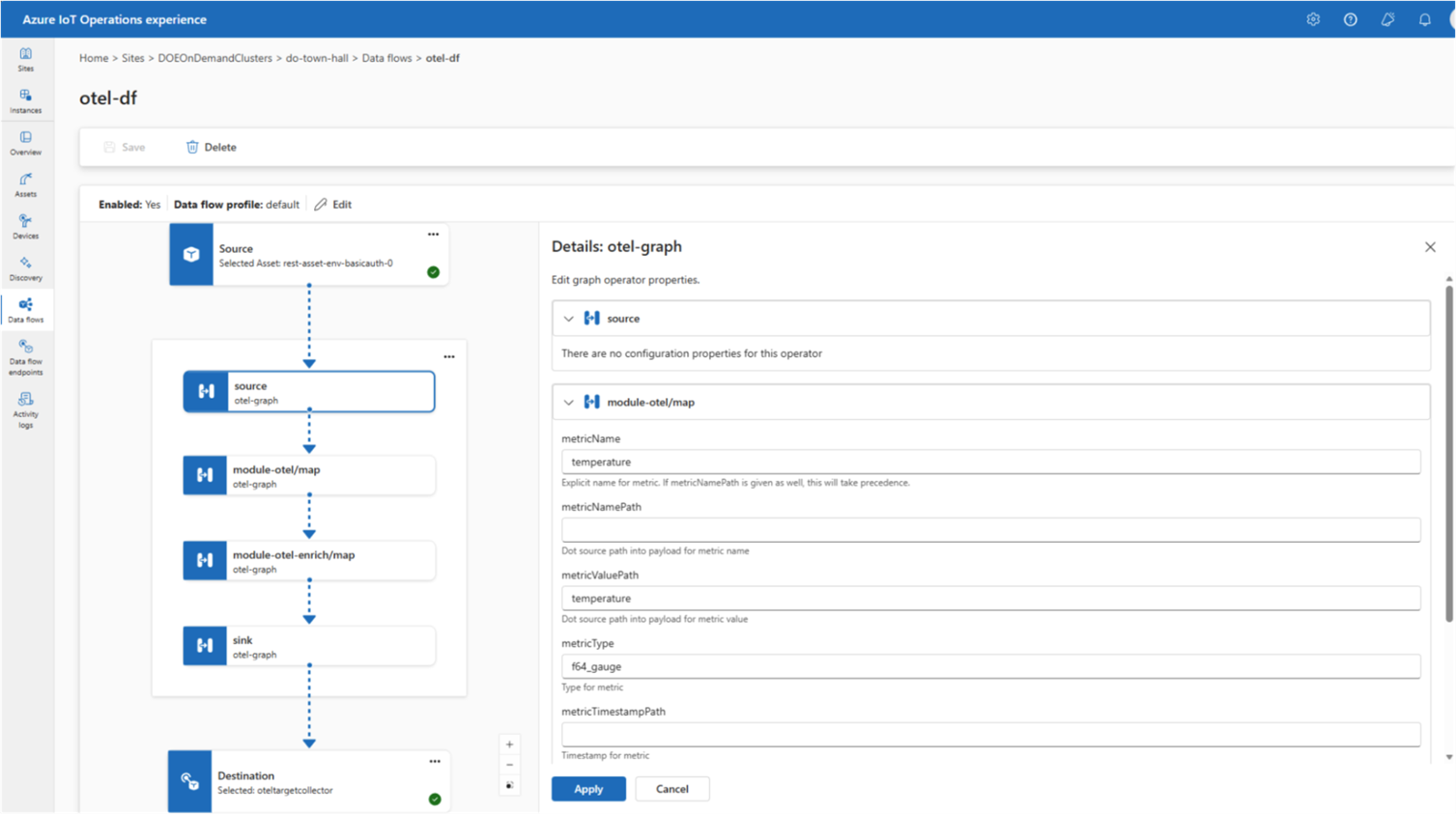
Azure IoT Operations now supports WebAssembly (Wasm)-powered data graphs, delivering fast, modular analytics right at the edge — eliminating the need to round-trip data to the cloud to get a decision back.
Wasm’s lightweight, sandboxed execution model is a natural fit for edge environments where compute is constrained, and every millisecond of latency matters. The modular nature of data graphs allows you to compose them from reusable pieces and deploy them consistently across diverse hardware profiles. For industrial scenarios requiring near real-time responses, this represents a significant advancement.
Expanded Connector Support
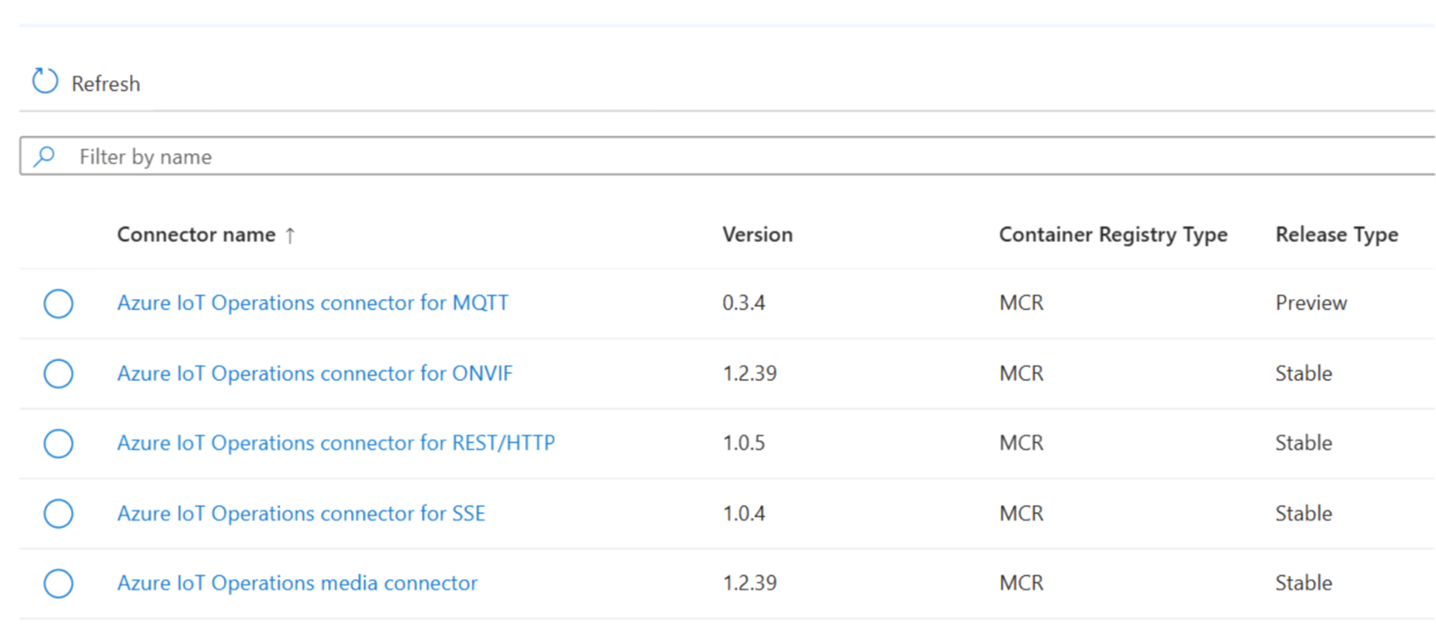
This release expands the connector library significantly. The newly supported connectors include:
- OPC UA: Industrial automation and SCADA systems
- ONVIF: IP-based physical security cameras and devices
- REST/HTTP: General-purpose web API integration
- Server-Sent Events (SSE): Real-time event streaming from HTTP sources
- Direct MQTT: Lightweight pub/sub messaging for IoT devices
This expanded set is a big deal for organizations that need to bridge industrial OT environments with modern IT systems without building custom middleware for every integration.
Data Flows Now Support OpenTelemetry
This is one of those updates that might not make headlines, but practitioners will appreciate it immediately. AIO data flows now include native OpenTelemetry (OTel) endpoint support.
OpenTelemetry has become the de facto standard for distributed tracing, metrics, and logging across the industry. Having AIO speak OpenTelemetry natively means you can route telemetry from edge devices directly into whatever observability platform you’re already using — Azure Monitor, Grafana, Datadog, you name it — without any additional transformation layers. Cleaner pipelines, less glue code.
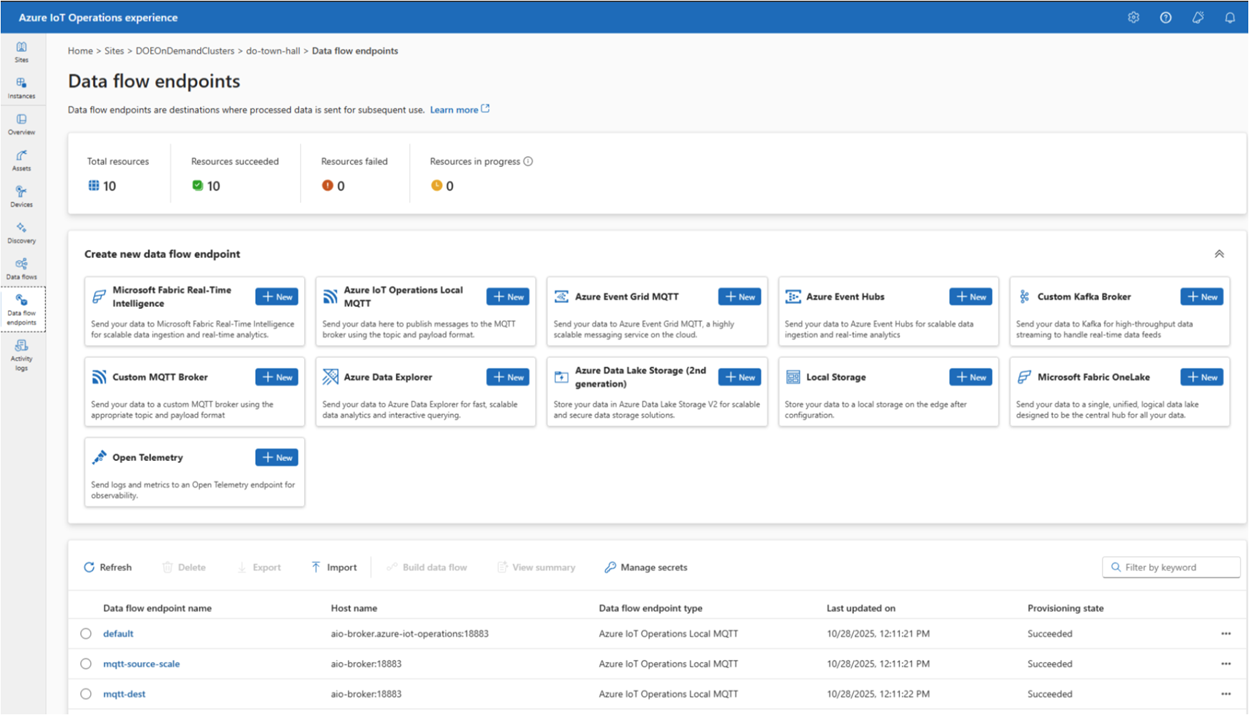
Device Support in Azure Device Registry
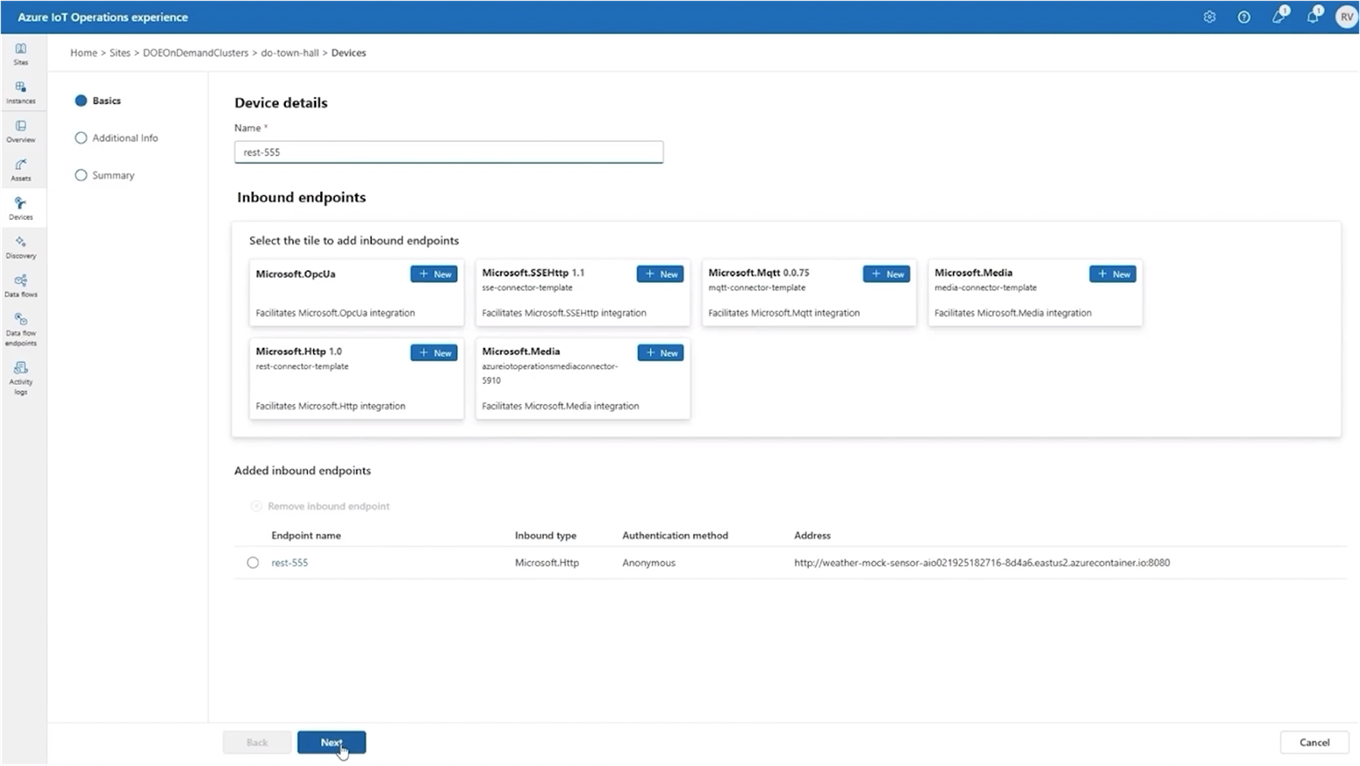
Azure Device Registry (ADR) got a meaningful upgrade here: devices are now treated as first-class resources within ADR namespaces.
In practice, this means:
- You can logically isolate devices within namespaces — critical for multi-tenant or multi-site deployments where you need clear boundaries
- RBAC can be applied at scale, so the right teams get the right level of access to the right devices without ad hoc workarounds
- Device management now aligns with the same resource model used everywhere else in Azure, which makes governance much more consistent
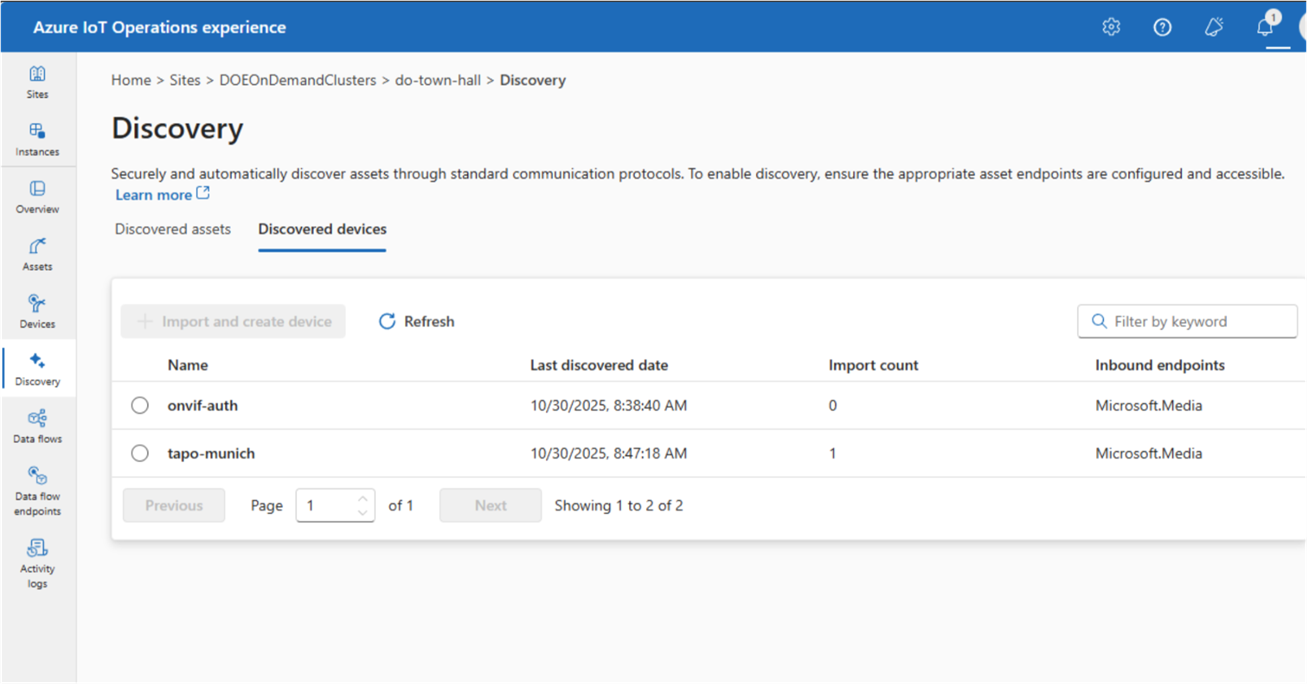
Automatic Device and Asset Discovery
If you’ve ever had to manually provision devices across a large factory floor, you know how painful it can be. This announcement addresses that head on. AIO now includes Akri-powered automatic discovery and onboarding:
- Continuously detects devices and industrial assets that appear on the network
- Automatically provisions and onboards newly discovered devices
- Gets telemetry flowing with minimal manual setup
For large-scale deployments, this can dramatically compress rollout timelines and free up your team from repetitive provisioning work. It’s the kind of operational improvement that compounds over time.
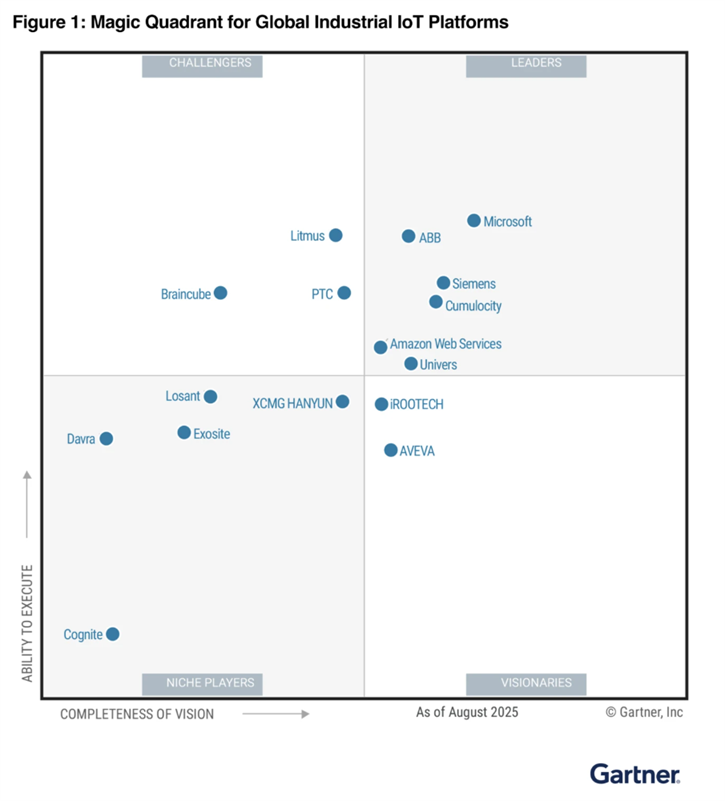
Microsoft Named a Leader in the 2025 Gartner® Magic Quadrant
I want to close the announcements on a high note. At Ignite 2025, Microsoft shared that it had been named a Leader in the 2025 Gartner® Magic Quadrant for Global Industrial IoT Platforms. As someone who works closely in this space, I think this recognition is well-deserved and reflects how much AIO has matured as a platform over the past couple of years.
Summary
Azure IoT Operations is moving fast, and the Ignite 2025 announcements show that Microsoft is serious about making it the go-to platform for intelligent, AI-driven operations at the edge. From Wasm-powered analytics and a broader connector library, to native OTel support and automated device discovery, there’s something here for nearly every team working in the industrial IoT space. I’m excited to see what comes next.
Enjoy!
References
- General Availability of Azure IoT Operations 2510 — Release announcement
- Azure IoT Operations Documentation — Official docs
- Azure IoT Blog — Latest news and updates
- Metro Toronto Azure Community – November 2025 Meetup — Event page
