The Durable Task Scheduler Consumption SKU has reached General Availability. If you’ve been waiting for a production-ready, pay-per-use orchestration backend for your durable workflows and AI agents on Azure — this is it. For anyone building on Azure Functions or Container Apps, this is worth paying attention to.
What is the Durable Task Scheduler?
The Durable Task Scheduler is a fully managed orchestration backend for durable execution on Azure. It handles task scheduling, state persistence, fault tolerance, and monitoring — so your workflows and agent sessions can reliably resume and run to completion through process failures, restarts, and scaling events, without you managing your own execution engine or storage backend.
It works across Azure compute environments:
Azure Functions — via the Durable Functions extension, across all plan types including Flex Consumption
Azure Container Apps — using Durable Functions or Durable Task SDKs with built-in workflow support and auto-scaling
Any compute — AKS, App Service, or any environment running the Durable Task SDKs (.NET, Python, Java, JavaScript)
Why the Consumption SKU Matters
Until this GA, the pay-per-use Consumption SKU was in public preview (since November 2025), while the Dedicated SKU was already the GA option for reserved capacity and higher-scale workloads. The Consumption SKU flips the model for lower-scale and variable-usage scenarios: you’re charged only for actions dispatched — with no idle costs, no minimum commitments, and no throughput to pre-size. You still pay separately for the Azure compute hosting your workflows; what the Consumption SKU removes is preprovisioned scheduler capacity and its associated idle cost.
This makes it a natural fit for workloads with spiky or unpredictable usage:
AI agent orchestration — multi-step agent workflows calling LLMs, retrieving data, and taking actions on demand
Event-driven pipelines — processing queues, webhooks, or streams with reliable checkpointing
API-triggered workflows — user signups, payment flows, and other request-driven processing
Distributed transactions — retry and compensation logic across microservices using durable sagas
The Consumption SKU supports up to 500 actions per second and 30 days of data retention, with a built-in dashboard for filtering orchestrations, drilling into execution history, viewing visual Gantt and sequence charts, and managing instances (pause, resume, terminate, raise events) — all secured with Entra ID and RBAC. No SAS tokens or access keys. If you need more throughput or longer retention, Dedicated remains the better fit.
Read the Full Announcement
For the complete details — including billing specifics, GA hardening changes from the preview, and links to getting started — read the full announcement:
In my Running and Building Azure Functions with Modern .NET talk last week at the Mississauga .NET User Group, the session covered a handful of topics that I think every .NET developer building on Azure Functions should know about — upgrading to .NET 10, centralizing package management, and the new solution file format. This is the first in a short series of posts walking through each of those topics. Let’s start with .NET 10 support in Azure Functions and what’s new.
.NET 10 is Now Supported in Azure Functions
Azure Functions now supports .NET 10 on runtime version 4.x, and it’s a big deal for anyone who cares about building modern, long-lived serverless applications. .NET 10 support runs until November 14, 2028, so you’ve got a solid runway once you’re on it.
A few things to keep in mind before you start your upgrade:
Only the isolated worker model supports .NET 10. The in-process model is not receiving a .NET 10 update and reaches end of support on November 10, 2026. If you haven’t started migrating off in-process, that date should be your motivation to get moving.
.NET 10 runs on Functions 4.x across most hosting plans. The one exception is Linux Consumption, which will not receive .NET 10 support. If that’s your current plan, Flex Consumption is the migration target.
The base container images have shifted from Debian to Ubuntu with .NET 10. If you have custom container builds, verify this against the official release notes before upgrading.
Minimum package versions required for .NET 10:
Package
Minimum Version
Microsoft.Azure.Functions.Worker
2.50.0
Microsoft.Azure.Functions.Worker.Sdk
2.0.5
Make sure you’re on at least these versions or the runtime will not load correctly.
Before You Upgrade — Quick Checklist
[ ] Confirm you’re on the isolated worker model (not in-process)
[ ] Confirm your hosting plan supports .NET 10 (see above)
[ ] Update Microsoft.Azure.Functions.Worker and Microsoft.Azure.Functions.Worker.Sdk to the minimum versions above
[ ] If migrating from in-process: swap Microsoft.NET.Sdk.Functions for Microsoft.Azure.Functions.Worker.Sdk, and replace Microsoft.Azure.WebJobs.* packages with Microsoft.Azure.Functions.Worker.Extensions.* equivalents
[ ] Verify your HTTP integration choice (see builder pattern section below)
[ ] Test locally with Azure Functions Core Tools v4
The New FunctionsApplication Builder Pattern
The biggest developer-facing change in .NET 10 (and technically available since .NET 8 with certain configurations) is the switch to the FunctionsApplication.CreateBuilder pattern. If you’ve been building with the older HostBuilder approach, this will feel familiar but noticeably cleaner.
Note:ConfigureFunctionsWebApplication() is for functions apps that use ASP.NET Core HTTP integration — it wires up the ASP.NET Core middleware pipeline. If your app is non-HTTP (queue triggers, timers, Service Bus, etc.) and you don’t need that integration, use ConfigureFunctionsWorkerDefaults() instead. Most starter templates will choose the right one, but it’s worth knowing what each does.
It’s a small surface area change but the intent is meaningful. Let me walk through why this matters.
Alignment with ASP.NET Core
ASP.NET Core has used WebApplication.CreateBuilder(args) since .NET 6. Azure Functions now mirrors this with FunctionsApplication.CreateBuilder(args). This consistency across .NET workloads is genuinely helpful — developers who work on both web APIs and Azure Functions no longer need to context-switch between two different initialization mental models.
Direct Access to the Services Collection
The old pattern required you to register services inside a ConfigureServices callback, which added an extra layer of nesting. With the new pattern, you access builder.Services directly — just like you would in an ASP.NET Core Program.cs. Cleaner, more readable, and easier to reason about.
Modern .NET Host Builder Infrastructure
Under the hood, the new pattern is built on HostApplicationBuilder, the modern hosting infrastructure introduced in .NET 6+. This brings with it better performance, improved configuration ordering, and enhanced hosting abstractions. It’s part of Microsoft’s broader effort to unify .NET across web apps, Azure Functions, Worker Services, and other application types — and honestly, it’s a move in the right direction.
If you’re migrating off Linux Consumption — or just evaluating where to run modern Azure Functions — Flex Consumption is where the platform is headed and worth understanding alongside your .NET 10 upgrade.
Flex Consumption is a Linux-based hosting plan built on a new backend internally called Legion. It keeps the serverless pay-for-what-you-use billing model you’re used to, but it adds a lot more control:
Scale to hundreds of instances in under a minute
Up to 1,000 scale-out instances (note: scale-out instances and per-instance concurrency are separate concepts — you configure concurrency independently)
Configurable per-instance concurrency
VNET integration with scale-to-zero still supported
Always-ready instances that reduce cold-start latency (optional; default is 0, so you pay only when you need them)
Multiple memory size options
Availability Zones support
If you’re building anything serious on Azure Functions right now, Flex Consumption paired with .NET 10 is where I’d be pointing you.
Summary
.NET 10 support in Azure Functions is a worthwhile upgrade. The migration from in-process to isolated worker model is no longer optional — with end of support coming November 2026 you need a plan. And once you’re on isolated worker with .NET 10, the new FunctionsApplication builder pattern makes initialization cleaner and more aligned with the rest of the .NET ecosystem. Pair that with a move to Flex Consumption and you’ve got a solid, modern foundation for your serverless workloads.
In the next posts in this series I’ll cover Central Package Management and the new SLNX solution file format — two more improvements that make the .NET developer experience noticeably better.
Last week, on December 4th, I presented at the Metro Toronto Azure Community meetup, discussing Microsoft’s announcements for Azure IoT Operations (AIO) at Ignite 2025. It was a fantastic evening — fellow MVPs Cliff Agius, Sander Van De Velde, Pete Gallagher, and Jose Simoes also took the stage with their own sessions on various Azure IoT topics.
IoT is a hobby interest of mine, so I genuinely enjoy keeping an eye on what’s happening in this space. When the Ignite announcements dropped, I was already deep in the details, which made putting the session together a lot of fun. This post is the written companion to that talk — a handy reference if you attended and want to revisit anything, or a full walkthrough if you missed it.
What is Azure IoT Operations?
If you’re new to Azure IoT Operations, let me give you a quick grounding before we jump into the announcements. AIO is AI-ready infrastructure for intelligent, adaptive operations. I describe it as more than a data pipeline — it serves as the foundation for integrating AI into the physical world. It enables systems that can perceive, reason, and act, which is precisely what modern industrial environments need to drive real operational efficiency.
What makes AIO stand out:
Built on Arc-enabled Kubernetes, ensuring a consistent management plane whether you’re on-premises, at the edge, or in the cloud
Unifies OT and IT data across distributed sites — effectively breaking down those frustrating silos between operational and business systems
Provides a repeatable, scalable platform that you can deploy across sites without starting from scratch each time
Extends familiar Azure management concepts to physical locations, which is significant for teams that are already acquainted with Azure.
Ignite 2025 Announcements at a Glance
The Ignite 2025 announcements for Azure IoT Operations are centered on three significant themes:
New edge-to-cloud orchestration capabilities
Tighter integration with Microsoft Fabric and Foundry
AI-driven observability and governance tools
Let’s explore each of the specific features that were announced.
Wasm-Powered Data Graphs
Azure IoT Operations now supports WebAssembly (Wasm)-powered data graphs, delivering fast, modular analytics right at the edge — eliminating the need to round-trip data to the cloud to get a decision back.
Wasm’s lightweight, sandboxed execution model is a natural fit for edge environments where compute is constrained, and every millisecond of latency matters. The modular nature of data graphs allows you to compose them from reusable pieces and deploy them consistently across diverse hardware profiles. For industrial scenarios requiring near real-time responses, this represents a significant advancement.
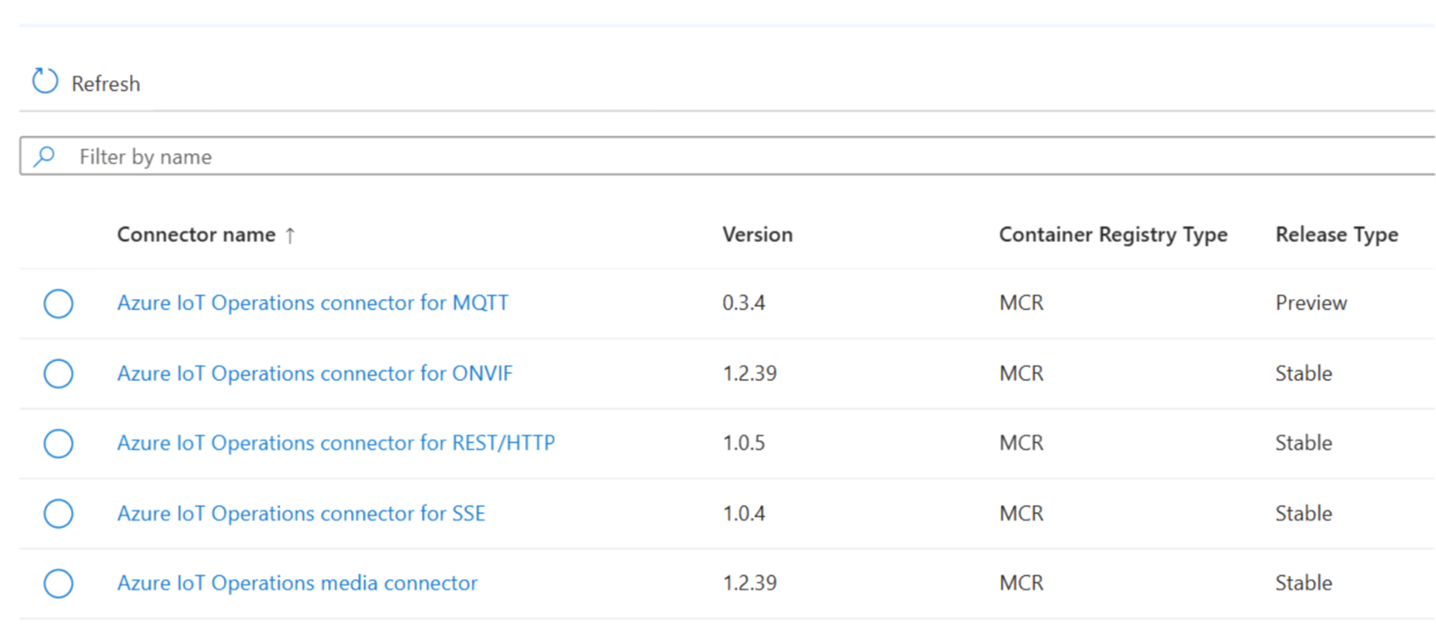
Expanded Connector Support
This release expands the connector library significantly. The newly supported connectors include:
OPC UA: Industrial automation and SCADA systems
ONVIF: IP-based physical security cameras and devices
REST/HTTP: General-purpose web API integration
Server-Sent Events (SSE): Real-time event streaming from HTTP sources
Direct MQTT: Lightweight pub/sub messaging for IoT devices
This expanded set is a big deal for organizations that need to bridge industrial OT environments with modern IT systems without building custom middleware for every integration.
Data Flows Now Support OpenTelemetry
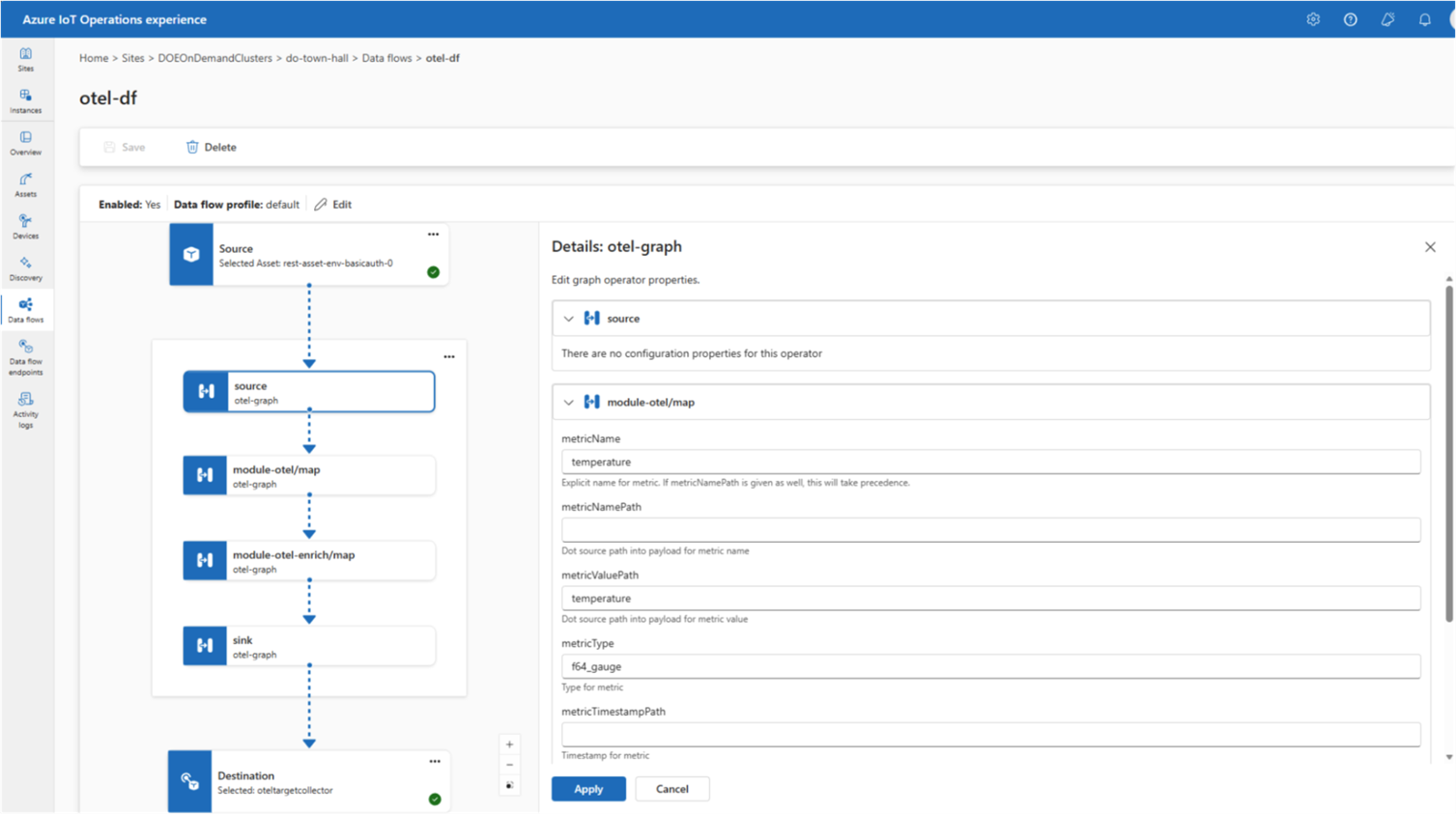
This is one of those updates that might not make headlines, but practitioners will appreciate it immediately. AIO data flows now include native OpenTelemetry (OTel) endpoint support.
OpenTelemetry has become the de facto standard for distributed tracing, metrics, and logging across the industry. Having AIO speak OpenTelemetry natively means you can route telemetry from edge devices directly into whatever observability platform you’re already using — Azure Monitor, Grafana, Datadog, you name it — without any additional transformation layers. Cleaner pipelines, less glue code.
Device Support in Azure Device Registry
Azure Device Registry (ADR) got a meaningful upgrade here: devices are now treated as first-class resources within ADR namespaces.
In practice, this means:
You can logically isolate devices within namespaces — critical for multi-tenant or multi-site deployments where you need clear boundaries
RBAC can be applied at scale, so the right teams get the right level of access to the right devices without ad hoc workarounds
Device management now aligns with the same resource model used everywhere else in Azure, which makes governance much more consistent
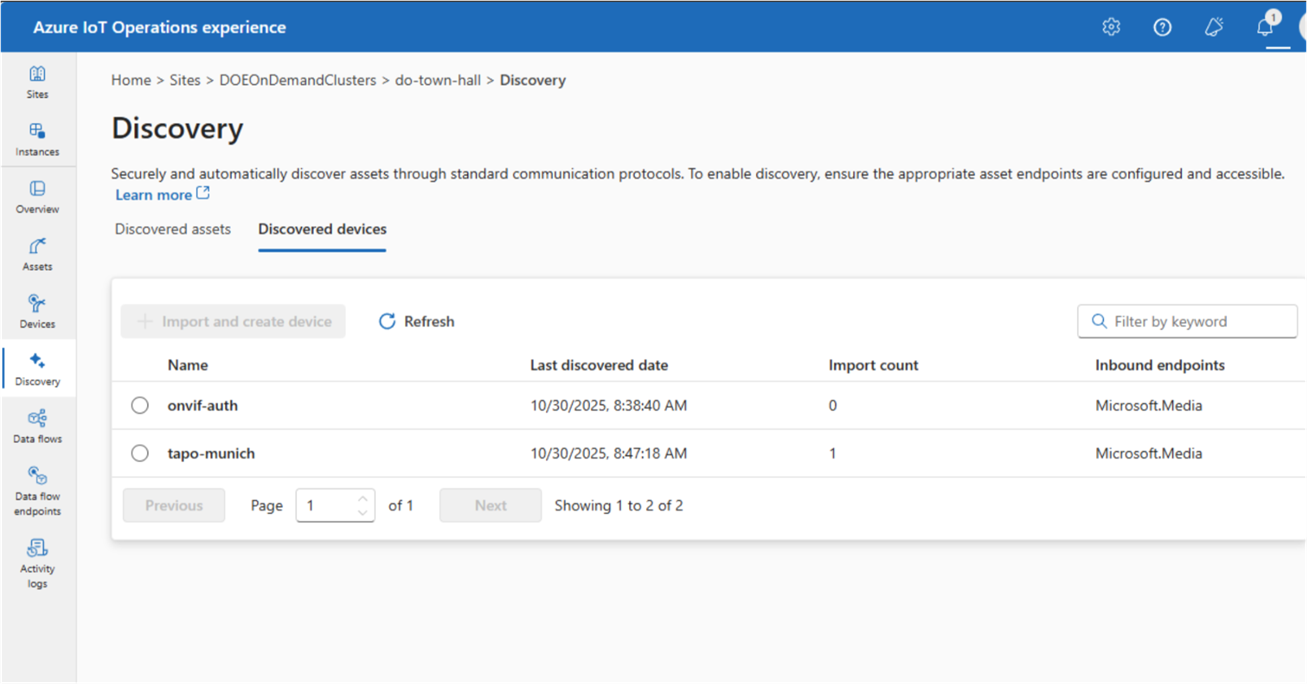
Automatic Device and Asset Discovery
If you’ve ever had to manually provision devices across a large factory floor, you know how painful it can be. This announcement addresses that head on. AIO now includes Akri-powered automatic discovery and onboarding:
Continuously detects devices and industrial assets that appear on the network
Automatically provisions and onboards newly discovered devices
Gets telemetry flowing with minimal manual setup
For large-scale deployments, this can dramatically compress rollout timelines and free up your team from repetitive provisioning work. It’s the kind of operational improvement that compounds over time.
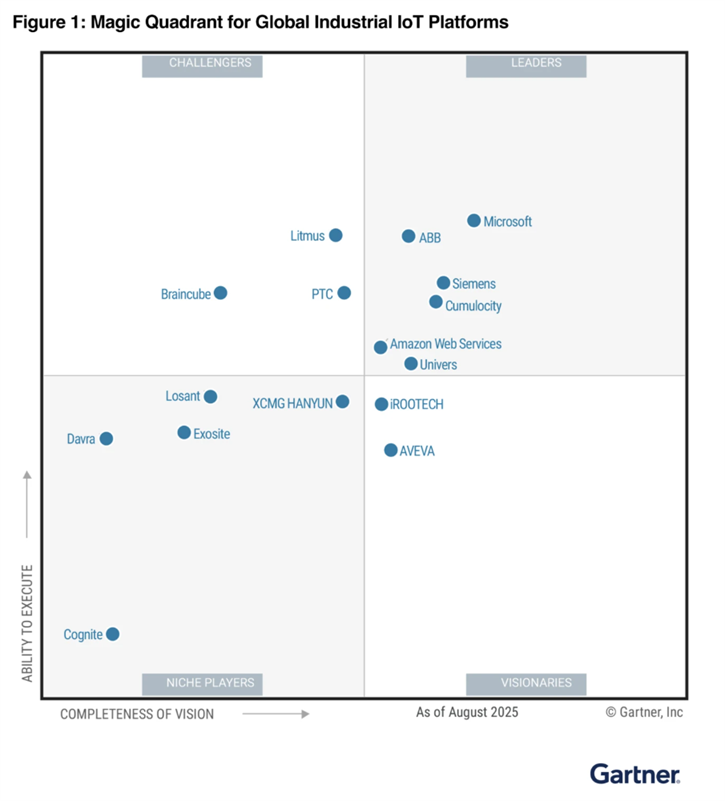
Microsoft Named a Leader in the 2025 Gartner® Magic Quadrant
I want to close the announcements on a high note. At Ignite 2025, Microsoft shared that it had been named a Leader in the 2025 Gartner® Magic Quadrant for Global Industrial IoT Platforms. As someone who works closely in this space, I think this recognition is well-deserved and reflects how much AIO has matured as a platform over the past couple of years.
Summary
Azure IoT Operations is moving fast, and the Ignite 2025 announcements show that Microsoft is serious about making it the go-to platform for intelligent, AI-driven operations at the edge. From Wasm-powered analytics and a broader connector library, to native OTel support and automated device discovery, there’s something here for nearly every team working in the industrial IoT space. I’m excited to see what comes next.
It’s that time of year for Microsoft Ignite and during this conference we usually see updates across a number of Azure services. If there’s one Azure service I always keep a close eye on, it’s Azure Functions. It sits squarely in my primary area of focus — Azure PaaS — and the Ignite 2025 announcements from the team were genuinely impressive. I won’t rehash the full product announcement here (the Azure Functions team blog post does that well), but I do want to call out the things that caught my attention and explain why they matter from where I sit.
Functions is Becoming the AI Execution Layer
Reading through the announcements, I like that Microsoft is positioning Azure Functions as a natural runtime for AI workloads — specifically MCP servers and agent-hosted tools. There are two distinct paths here worth separating:
GA: Author MCP tool servers using the familiar Functions triggers-and-bindings model — Functions handles the protocol mechanics and scaling.
Preview: Host existing official MCP SDK servers directly on Functions without rewriting them as triggers.
The GA path is the more practical entry point for most teams. It means you can build remote MCP servers using patterns you already know, and Functions handles all the protocol mechanics and scaling underneath.
There’s also built-in authentication via Entra ID and OpenID Connect for MCP servers, which addresses the main gap from the early preview. Worth noting: authorization currently secures access at the server level, not per individual tool, and fine-grained per-resource-management (PRM) authorization is still in preview. Good progress, but something to factor in before going all-in on this for production workloads.
Flex Consumption Keeps Getting Better
Azure Functions Flex Consumption is the new default hosting model and it’s the right hosting choice for most new Azure Functions workloads. The Ignite 2025 updates reinforce that view. A few highlights:
512 MB instance size is now GA — right-sizing lighter workloads without paying for more memory than you need
Availability Zones is now GA — the last real holdout for production-critical workloads is gone
Rolling updates hit public preview — zero-downtime deployments by setting a single property; in-flight executions drain naturally before instances are replaced
That last one is worth keeping an eye on, but it’s still public preview and not recommended for production yet. There are also real caveats to be aware of: deployments need to be backward-compatible (especially important with Durable Functions), and single-instance apps can still see brief downtime during rollover. Still, zero-downtime deployment of Azure Functions has been a frequent customer ask and the direction is right. Outside of the Flex Consumption, we could use Deployment Slots for zero downtime deployments.
Durable Functions + AI Agents
The durable task extension for Microsoft Agent Framework is something I’ll be watching closely. The idea is straightforward: bring Durable Functions’ proven crash-resilient, distributed execution model into the Agent Framework. That means AI agents that survive restarts, maintain session context, and support human-in-the-loop patterns — all without consuming compute while waiting.
Key features of the durable task extension include:
Serverless Hosting: Deploy agents on Azure Functions with auto-scaling from thousands of instances to zero, while retaining full control in a serverless architecture.
Automatic Session Management: Agents maintain persistent sessions with full conversation context that survives process crashes, restarts, and distributed execution across instances
Human-in-the-Loop with Serverless Cost Savings: Pause for human input without consuming compute resources or incurring costs
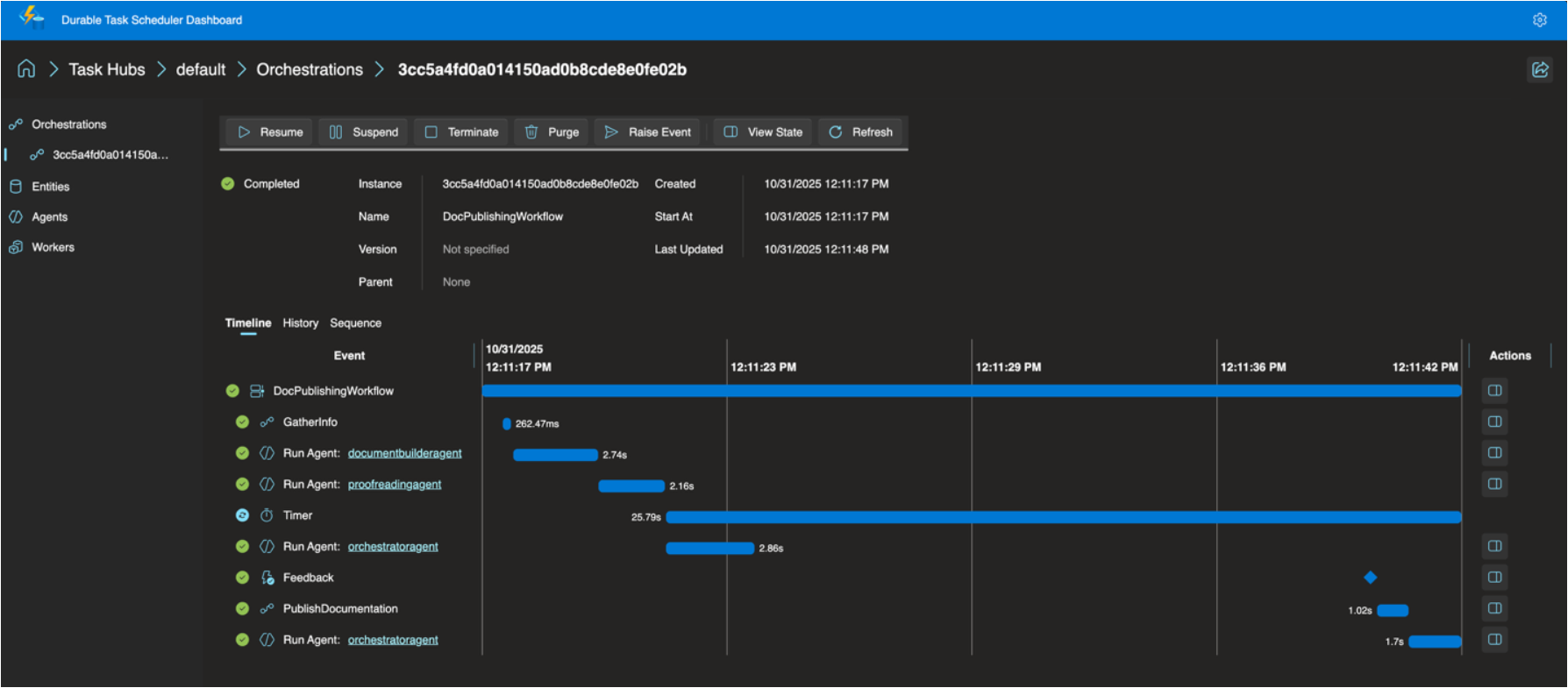
Built-in Observability with Durable Task Scheduler: Deep visibility into agent operations and orchestrations through the Durable Task Scheduler UI dashboard
For anyone building multi-step AI workflows where reliability and state management matter, this is worth understanding. The announcement post has more detail.
The Durable Task Scheduler Dedicated SKU also reached GA, which is good news for teams running complex, steady-state orchestrations that need predictable pricing and advanced monitoring. For context, the Durable Task Scheduler is the managed orchestration backend that powers Durable Functions execution — GA of the Dedicated SKU means production-grade support and SLAs for it. A serverless Consumption SKU for the scheduler is now in preview too.
OpenTelemetry GA
OpenTelemetry support for Azure Functions is now generally available. This one has been a long time coming. Logs, traces, and metrics through open standards — vendor-neutral, broadly supported, consistent with how the rest of your distributed system is already instrumented. Support spans .NET (isolated), Java, JavaScript, Python, PowerShell, and TypeScript. If your Functions apps are still relying on Application Insights SDK directly (I think that’s most of our apps), it’s worth looking at the OpenTelemetry migration docs. I’ll have to look at a follow-up post about this specifically.
A Few Other Things Worth Knowing
.NET 10 is now supported in the isolated worker model across all plans except Linux Consumption. The in-process model is not getting .NET 10 and reaches end of support November 10, 2026 — if you haven’t started that migration, now is the time.
Aspire 13 ships an updated preview of the Functions integration (acting as a release candidate), with GA expected in Aspire 13.1. It deploys directly to Azure Functions on Container Apps.
Java 25 and Node.js 24 were announced in preview at Ignite — check current docs for latest GA status.
There’s more in the full product update — including details on security improvements, new regions, Key Vault App Config references, and the self-hosting MCP SDK preview — than I’ve covered here. I’d recommend reading through the Azure Functions Ignite 2025 Update directly if you want the complete picture.
This week, Microsoft announced the public preview of geo-replication for Azure Event Hubs. Geo-replication enhances Microsoft Azure data availability and geo-disaster recovery capabilities by enabling the replication of Event Hubs data payloads across different Azure regions.
With geo-replication, your client applications continue to interact with the primary namespace. Customers can designate a secondary region, choose replication consistency (synchronous or asynchronous), and set replication lag for the data. The service handles the replication between primary and secondary regions. If a primary change is needed (for maintenance or failover), the secondary can be promoted to primary, seamlessly servicing all client requests without altering any configurations (connection strings, authentication, etc.). The former primary then becomes the secondary, ensuring synchronization between both regions.
In summary, geo-replication is designed to provide you with the following benefits:
High availability: You can ensure that your data is always accessible and durable, even in the event of a regional outage or disruption. You can also reduce the impact of planned maintenance events by switching to the secondary region before the primary region undergoes any updates or changes.
Disaster recovery: You can recover your data quickly and seamlessly in case of a disaster that affects your primary region. You can initiate a failover to the secondary region and resume your data streaming operations with minimal downtime and data loss.
Regional compliance: You can meet the regulatory and compliance requirements of your industry or region by replicating your data to a secondary region that complies with the same or similar standards as your primary region. You can also leverage the geo-redundancy of your data to support your business continuity and resilience plans.
How to get started with Azure Event Hubs Geo-replication?
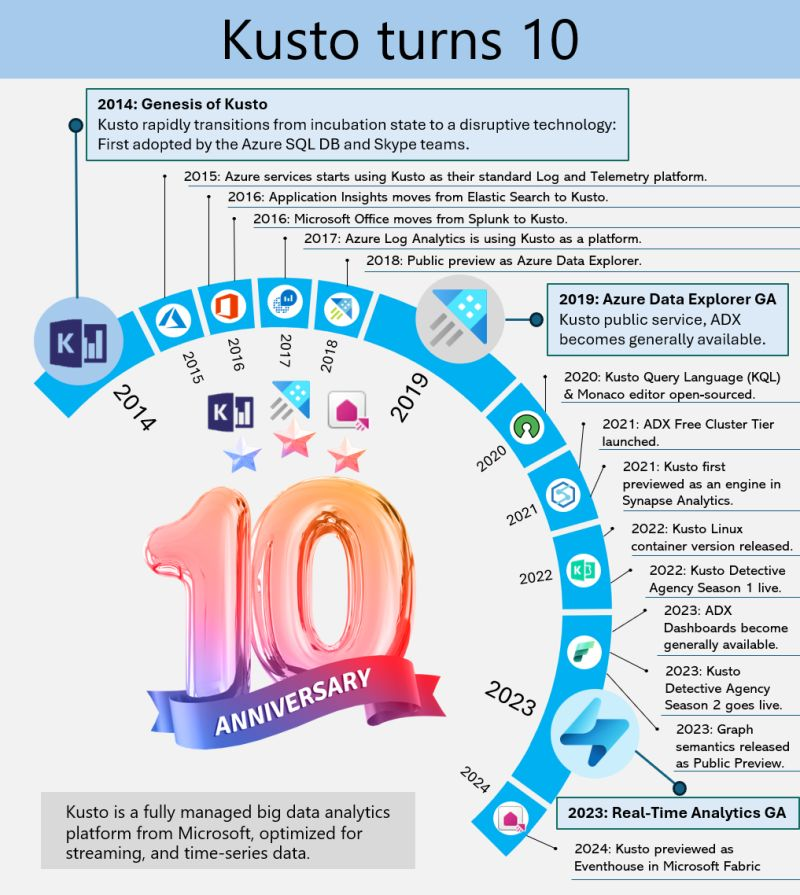
Kusto, the internal service driving Microsoft’s telemetry and several key services, recently marked its 10-year milestone. Over the decade, Kusto has evolved significantly, becoming the backbone for crucial applications such as Sentinel, Application Insights, Azure Data Explorer, and more recently, Eventhouse in Microsoft Fabric. This journey highlights its pivotal role in enhancing data processing, monitoring, and analytics across Microsoft’s ecosystem.
This powerful service has continually adapted to meet the growing demands of Microsoft’s internal and external data needs, underscoring its importance in the company’s broader strategy for data management and analysis.
A Dive into Azure Data Explorer’s Origins
Azure Data Explorer (ADX), initially code-named “Kusto,” has a fascinating backstory. In 2014, it began as a grassroots initiative at Microsoft’s Israel R&D center. The team wanted a name that resonated with their mission of exploring vast data oceans, drawing inspiration from oceanographer Jacques Cousteau. Kusto was designed to tackle the challenges of rapid and scalable log and telemetry analytics, much like Cousteau’s deep-sea explorations.
By 2018, ADX was officially unveiled at the Microsoft Ignite conference, evolving into a fully-managed big data analytics platform. It efficiently handles structured, semi-structured (like JSON), and unstructured data (like free-text). With its powerful querying capabilities and minimal latency, ADX allows users to swiftly explore and analyze data. Remembering its oceanic roots, ADX symbolizes a tribute to the spirit of discovery.
This week Microsoft announced in public preview, support for large messages (up to 20 MB) in Azure Event Hubs in its self-service scalable dedicated clusters, enhancing its capabilities to handle a wide range of message sizes without additional costs.
This new feature allows for seamless streaming of large messages without requiring any client code changes, maintaining compatibility with existing Event Hubs SDKs and the Kafka API. This enhancement ensures uninterrupted business operations by accommodating instances where messages cannot be divided into smaller segments. The service continues to offer high throughput and low latency, making it a robust solution for data streaming needs.
What are some cases for large message support?
Here are some key use cases for the new large message support in Azure Event Hubs:
Multimedia Streaming: Handling large video, audio, or image files that cannot be split into smaller segments.
Data Aggregation: Transmitting aggregated data sets or logs that exceed typical message size limits.
IoT Applications: Streaming large sensor data or firmware updates from IoT devices.
Batch Processing: Sending large batches of data for processing without needing to break them down.
These enhancements ensure seamless and uninterrupted business operations across various scenarios.
How do you enable large message support?
To enable large message support in your existing Azure Event Hubs setup, follow these steps:
Use Self-Serve Scalable Dedicated Clusters: Ensure your Event Hubs are built on the latest infrastructure that supports self-serve scalable dedicated clusters. If you are using Event Hubs, then you will need to create an Event Hub Cluster to take advantage of large message support.
No Client Code Changes Needed: You can continue using your existing Event Hubs SDK or Kafka API. The only change required is in the message or event size itself.
How do Azure Event Hubs differ from Azure Event Hub Clusters?
Azure Event Hubs and Event Hub Clusters serve different purposes within the Azure ecosystem:
Azure Event Hubs: This is a fully managed, real-time data ingestion service that can receive and process millions of events per second. It’s designed for high-throughput data streaming and is commonly used for big data and analytics.
Azure Event Hub Clusters: These are dedicated clusters that provide isolated resources for Event Hubs. They offer enhanced performance, scalability, and the ability to handle large messages (up to 20 MB). Clusters are ideal for scenarios requiring high throughput and low latency.
What is the Book of News? The Microsoft Build 2024 Book of News is your guide to the key news items announced at Build 2024.
As expected there is a lot of focus on Azure and AI, followed by Microsoft 365, Security, Windows, and Edge & Bing. This year the book of news is interactive instead of being a PDF.
Some of my favourite announcements
Azure Cloud Native and Application Platform
Azure Functions
Microsoft Azure Functions is launching several new features to provide more flexibility and extensibility to customers in this era of AI.
Features now in preview include:
A Flex Consumption plan that will give customers more flexibility and customization without compromising on available features to run serverless apps.
Extension for MicrosoftAzure OpenAIService that will enable customers to easily infuse AI in their apps. Customers will be able to use this extension to build new AI-led apps like retrieval-augmented generation, text completion and chat assistant.
Visual Studio Code for the Web will provide a browser-based developer experience to make it easier to get started with Azure Functions. This feature is available for Python, Node and PowerShell apps in the Flex Consumption hosting plan.
Features now generally available include:
Azure Functions on Azure Container Apps lets developers use the Azure Container Apps environment to deploy multitype services to a cloud-native solution designed for centralized management and serverless scale.
Dapr extension for Azure Functions enables developers to use Dapr’s powerful cloud native building block APIs and a large array of ecosystem components in the native and friendly Azure Functions triggers and bindings programming model. The extension is available to run on Azure Kubernetes Service and Azure Container Apps.
Azure Container Apps
Microsoft Azure Container Apps will include dynamic sessions, in preview, for AI app developers to instantly run large language model (LLM)-generated code or extend/customize software as a service (SaaS) apps in an on-demand, secure sandbox.
Customers will be able to mitigate risks to their security posture, leverage serverless scale for their apps and save months of development work, ongoing configurations and management of compute resources that reduce their cost overhead. Dynamic sessions will provide a fast, sandboxed, ephemeral compute suitable for running untrusted code at scale.
Additional new features, now in preview, include:
Support for Java: Java developers will be able to monitor the performance and health of apps with Java metrics such as garbage collection and memory usage.
Microsoft .NET Aspire dashboard: With dashboard support for .NET Aspire in Azure Container Apps, developers will be able to access live data about projects and containers in the cloud to evaluate the performance of .NET cloud-native apps and debug errors.
Azure App Service
Microsoft Azure App Service is a cloud platform to quickly build, deploy and run web apps, APIs and other components. These capabilities are now in preview:
Sidecar patterns is a way to add extra features to the main app, such as logging, monitoring and caching, without changing the app code. Users will be able to run these features alongside the app and it is supported for both source code and container-based deployments.
WebJobs will be integrated with Azure App Service, which means they will share the same compute resources as the web app to help save costs and ensure consistent performance. WebJobs are background tasks that run on the same server as the web app and can perform various functions, such as sending emails, executing bash scripts and running scheduled jobs.
GitHub Copilot skills for Azure Migrate will enable users to ask questions like, “Can I migrate this app to Azure?” or “What changes do I need to make to this code?” to get answers and recommendations from Azure Migrate. GitHub Copilot licenses are sold separately.
These capabilities are now generally available:
Automatic scaling continuously adjusts the number of servers that run apps based on a combination of demand and server utilization, without any code or complex scaling configurations. This helps users handle dynamically changing site traffic without over-provisioning or under-provisioning the app’s server resources.
Availability zones are isolated locations within an Azure region that provide high availability and fault tolerance. Enabling availability zones lets users take advantage of the increased service level agreement (SLA) of 99.99%. For more information, reference the SLA for App Service.
TLS 1.3 encryption, the latest version of the protocol that secures communication between apps and the clients, offers faster and more secure connections, as well as better compatibility with modern browsers and devices.
Azure Static Web Apps
To help customers deliver more advanced capabilities, Microsoft Azure Static Web Apps will offer a dedicated pricing plan, now in preview, that supports enterprise-grade features for enhanced networking and data storage. The dedicated plan for Azure Static Web Apps will utilize dedicated compute capacity and will enable:
Network isolation to enhance security.
Data residency to help customers comply with data management policies and requirements.
Enhanced quotas to allow for more custom domains within an app service plan.
“Always-on” functionality for Azure Static Web Apps managed functions, which provide built-in API endpoints to connect to backend services.
Azure Logic Apps
Microsoft Azure Logic Apps is a cloud platform where users can create and run automated workflows with little to no code. Updates to the platform include:
An enhanced developer experience:
Improved onboarding experience in Microsoft Visual Studio Code: A simplified extension installation experience and improvements on project start and debugging are now generally available.
Logic Apps Standard deployment scripting toolsin Visual Studio Code: This feature will simplify the process of setting up a continuous integration/continuous delivery (CI/CD) process for Logic Apps Standard by providing support in the tooling to generalize common metadata files and automate the creation of infrastructure scripts to streamline the task of preparing code for automated deployments. This feature is in preview.
Support for Zero Downtime deployment scenarios: This will enable Zero Downtime deployment scenarios for Logic Apps Standard by providing support for deployment slots in the portal. This update is in preview.
Expanded functionality and compatibility with Logic Apps Standard:
.NET Custom Code Support: Users will be able to extend low-code workflows with the power of .NET 8 by authoring a custom function and calling from a built-in action within the workflow. This feature is in preview.
Logic Apps connectors for IBM mainframe and midranges: These connectors allow customers to preserve the value of their workloads running on mainframes and midranges by allowing them to extend to the Azure Cloud without investing more resources in the mainframe or midrange environments using Azure Logic Apps. This update is generally available.
Other updates, in preview, include Azure Integration account enhancements and Logic Apps monitoring dashboard.
Azure API Center
Microsoft Azure API Center, now generally available, provides a centralized solution to manage the challenges of API sprawl, which is exacerbated by the rapid proliferation of APIs and AI solutions. The Azure API Center offers a unified inventory for seamless discovery, consumption and governance of APIs, regardless of their type, lifecycle stage or deployment location. This enables organizations to maintain a complete and current API inventory, streamline governance and accelerate consumption by simplifying discovery.
Azure API Management
Azure API Management has introduced new capabilities to enhance the scalability and security of generative AI deployments. These include the Microsoft Azure OpenAI Service token limit policy for fair usage and optimized resource allocation, one-click import of Azure OpenAI Service endpoints as APIs, a Load Balancer for efficient traffic distribution and a Circuit breaker to protect backend services.
Other updates, now generally available, include first-class support for OData API type, allowing easier publication and security of OData APIs, and full support for gRPC API type in self-hosted gateways, facilitating the management of gRPC services as APIs.
Azure Event Grid
Microsoft Azure Event Grid has new features that are tailored to customers who are looking for a pub-sub message broker that can enable Internet of Things (IoT) solutions using MQTT protocol and can help build event-driven apps. These capabilities enhance Event Grid’s MQTT broker capability, make it easier to transition to Event Grid namespaces for push and pull delivery of messages, and integrate new sources. Features now generally available include:
Use the Last Will Testament feature, in compliance with MQTT v5 and MQTT v.3.1.1 specifications, so apps receive notifications when clients get disconnected, enabling management of downstream tasks to prevent performance degradation.
Create data pipelines that utilize both Event Grid Basic resources and Event Grid Namespace Topics (supported in Event Grid Standard). This means customers can utilize Event Grid namespace capabilities, such as MQTT broker, without needing to reconstruct existing workflows.
Support new event sources, such as Microsoft Entra ID and Microsoft Outlook, leveraging Event Grid’s support for the Microsoft Graph API. This means customers can use Event Grid for new use cases, like when a new employee is hired or a new email is received, to process that information and send to other apps for more action.
Azure Data Platform
Real-Time Intelligence in Microsoft Fabric
The new Real-Time Intelligence within Microsoft Fabric will provide an end-to-end software as a service (SaaS) solution that will empower customers to act on high volume, time-sensitive and highly granular data in a proactive and timely fashion to make faster and more-informed business decisions. Real-Time Intelligence, now in preview, will empower user roles such as everyday analysts with simple low-code/no-code experiences, as well as pro developers with code-rich user interfaces.
Features of Real-Time Intelligence will include:
Real-Time hub, a single place to ingest, process and route events in Fabric as a central point for managing events from diverse sources across the organization. All events that flow through Real-Time hub will be easily transformed and routed to any Fabric data stores.
Event streams that will provide out-of-the-box streaming connectors to cross cloud sources and content-based routing that helps remove the complexity of ingesting streaming data from external sources.
Event house and real-time dashboards with improved data exploration to assist business users looking to gain insights from terabytes of streaming data without writing code.
Data Activator that will integrate with the Real-Time hub, event streams, real-time dashboards and KQL query sets, to make it seamless to trigger on any patterns or changes in real-time data.
AI-powered insights, now with an integrated Microsoft Copilot in Fabric experience for generating queries, in preview, and a one-click anomaly detection experience, allowing users to detect unknown conditions beyond human scale with high granularity in high-volume data, in private preview.
Event-Driven Fabric will allow users to respond to system events that happen within Fabric and trigger Fabric actions, such as running data pipelines.
New capabilities and updates to Microsoft Fabric
Microsoft Fabric, the unified data platform for analytics in the era of AI, is a powerful solution designed to elevate apps, whether a user is a developer, part of an organization or an independent software vendor (ISV). Updates to Fabric include:
Fabric Workload Development Kit: When building an app, it must be flexible, customizable and efficient. Fabric Workload Development Kit will make this possible by enabling ISVs and developers to extend apps within Fabric, creating a unified user experience.This feature is now in preview.
Fabric Data Sharingfeature: Enables real-time data sharing across users and apps. The shortcut feature API allows seamless access to data stored in external sources to perform analytics without the traditional heavy integration tax. The new Automation feature now streamlines repetitive tasks resulting in less manual work, fewer errors and more time to focus on the growth of the business. These features are now in preview.
GraphQL APIanduser data functions in Fabric: GraphQL API in Fabric is a savvy personal assistant for data. It’s a RESTful API that will let developers access data from multiple sources within Fabric, using a single query. User data functions will enhance data processing efficiency, enabling data-centric experiences and apps using Fabric data sources like lakehouses, data warehouses and mirrored databases using native code ability, custom logic and seamless integration.These features are now in preview.
AI skills in Fabric: AI skills in Fabric is designed to weave generative AI into data specific work happening in Fabric. With this feature, analysts, creators, developers and even those with minimal technical expertise will be empowered to build intuitive AI experiences with data to unlock insights. Users will be able to ask questions and receive insights as if they were asking an expert colleague while honoring user security permissions.This feature is now in preview.
Copilot in Fabric: Microsoft is infusing Fabric with Microsoft Azure OpenAI Service at every layer to help customers unlock the full potential of their data to find insights. Customers can use conversational language to create dataflows and data pipelines, generate code and entire functions, build machine learning models or visualize results. Copilot in Fabric is generally available in Power BI and available in preview in the other Fabric workloads.
Azure Cosmos DB
Microsoft Azure Cosmos DB, the database designed for AI that allows creators to build responsive and intelligent apps with real-time data ingested and processed at any scale, has several key updates and new features that include:
Built-in vector database capabilities: Azure Cosmos DB for NoSQL will feature built-in vector indexing and vector similarity search, enabling data and vectors to be stored together and to stay in sync. This will eliminate the need to use and maintain a separate vector database. Powered by DiskANN, available in June, Azure Cosmos DB for NoSQL will provide highly performant and highly accurate vector search at any scale. This feature is now in preview.
Serverless to provisioned account migration: Users will be able to transition their serverless Azure Cosmos DB accounts to provisioned capacity mode. With this new feature, transition can be accomplished seamlessly through the Azure portal or Azure command-line interface (CLI). During this migration process, the account will undergo changes in-place and users will retain full access to Azure Cosmos DB containers for data read and write operations.This feature is now in preview.
Cross-region disaster recovery: With disaster recovery in vCore-based Azure Cosmos DB for MongoDB a cluster replica can be created in another region. This cluster replica will be continuously updated with the data written in the primary region. In a rare case of outage in the primary region and primary cluster unavailability, this replica can be promoted to become the new read-write cluster in another region. Connection string is preserved after such a promotion, so that apps can continue to read and write to the database in another region using the same connection string. This feature is now in preview.
Azure Cosmos DB Vercel integration: Developers building apps using Vercel can now connect easily to an existing Azure Cosmos DB database or create new Azure Try Cosmos DB accounts on the fly and integrate them to their Vercel projects. This integration improves productivity by creating apps easily with a backend database already configured. This also helps developers onboard to Azure Cosmos DB faster. This feature is now generally available.
Go SDK for Azure Cosmos DB: The Go SDK allows customers to connect to an Azure Cosmos DB for NoSQL account and perform operations on databases, containers and items. This release brings critical Azure Cosmos DB features for multi-region support and high availability to Go, such as the ability to set preferred regions, cross-region retries and improved request diagnostics. This feature is now generally available.
For the past few months, I’ve been diving into learning Azure Data Explorer (ADX) and using it for a few projects. What is Azure Data Explorer, and what would I use it for? Great questions. Azure Data Explorer is like your data’s best friend when it comes to real-time, heavy-duty analytics. It’s built to handle massive amounts of data—whether it’s structured, semi-structured, or all over the place—and turn it into actionable insights. With its star feature, the Kusto Query Language (KQL), you can dive deep into the data for tasks like spotting trends, detecting anomalies, or analyzing logs, all with ease. It’s perfect for high-speed data streams, making it a go-to for IoT and time-series data. Plus, it’s secure, scalable, and does the hard work fast so you can focus on making more intelligent decisions.
When to use Azure Data Explorer
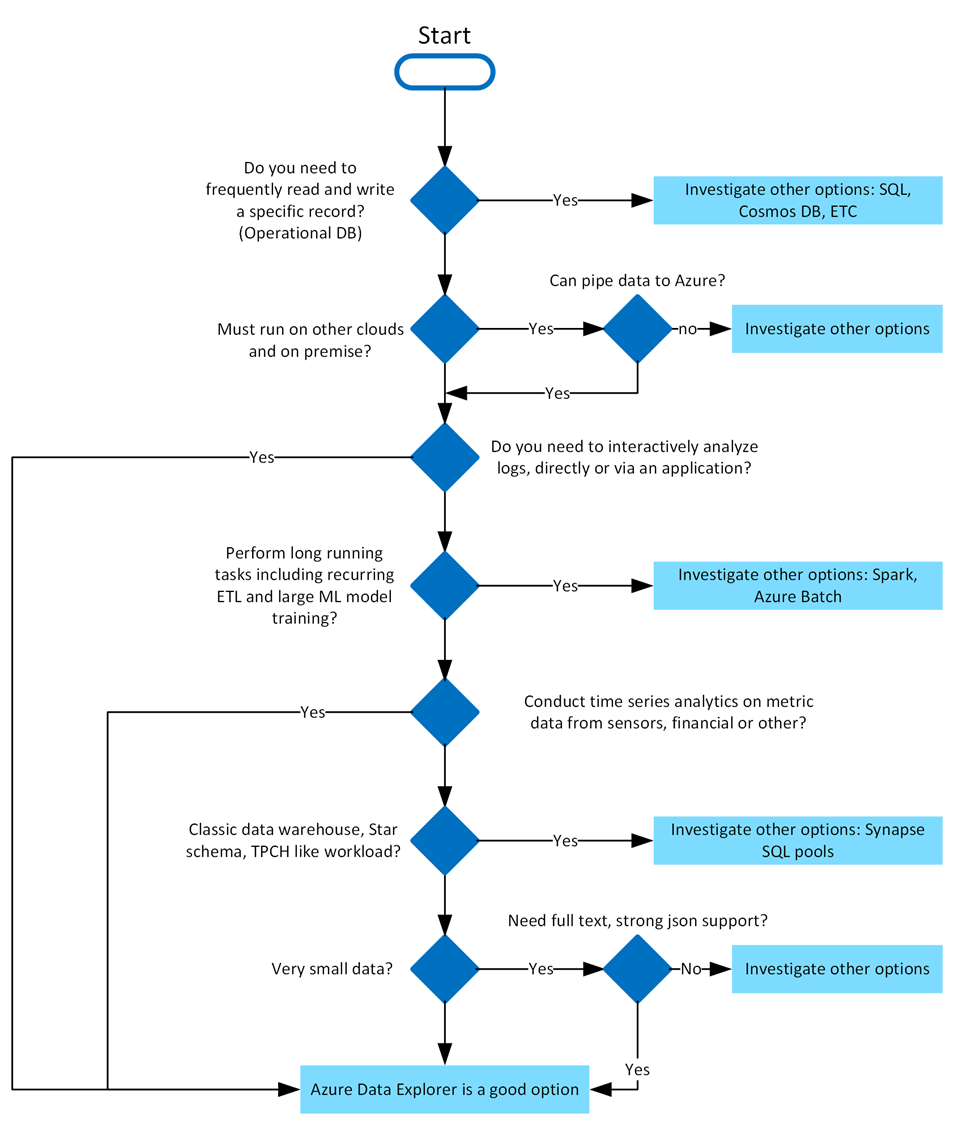
Azure Data Explorer is ideal for enabling interactive analytics capabilities over high-velocity, diverse raw data. Use the following decision tree to help you decide if Azure Data Explorer is right for you:
What makes Azure Data Explorer unique
Azure Data Explorer stands out due to its exceptional capabilities in handling vast amounts of diverse data quickly and efficiently. It supports high-speed data ingestion (terabytes in minutes) and querying of petabytes with millisecond-level results. Its Kusto Query Language (KQL) is intuitive yet powerful, enabling advanced analytics and seamless integration with Python and T-SQL. With specialized features for time series analysis, anomaly detection, and geospatial insights, it’s tailored for deep data exploration. The platform simplifies data ingestion with its user-friendly wizard, while built-in visualization tools and integrations with Power BI, Grafana, Tableau, and more make insights accessible. It also automates data ingestion, transformation, and export, ensuring a smooth, end-to-end analytics experience.
A Kusto query is a read-only request to process data and return results.
Has one or more query statements and returns data in a tabular or graph format.
Statements are sequenced by a pipe (|).
Data flows, or is piped, from one operator to the next.
The data is filtered/manipulated at each step and then fed into the following step.
Each time the data passes through another operator, it’s filtered, rearranged, or summarized.
Here is the above query:
StormEvents
| where StartTime >= datetime(2007-11-01)
| where StartTime <= datetime(2007-12-01)
| where State == 'FLORIDA'
| count
Azure Data Explorer query editor also supports the use of T-SQL in addition to its primary query language, Kusto query language (KQL). While KQL is the recommended query language, T-SQL can be useful for tools that are unable to use KQL. For more details, check out how to query data with T-SQL.
Using commands to manage Azure Data Explorer tables
When it comes to writing commands for managing tables, the first character of the text of a request determines if the request is a management command or a query. Management commands must start with the dot (.) character, and no query may start with that character.
Here are some examples of management commands:
.create table
.create-merge table
.drop table
.alter table
.rename column
Getting started
You can try Azure Data Explorer for free using the free cluster. Head over to https://dataexplorer.azure.com/ and log in with any Microsoft Account.
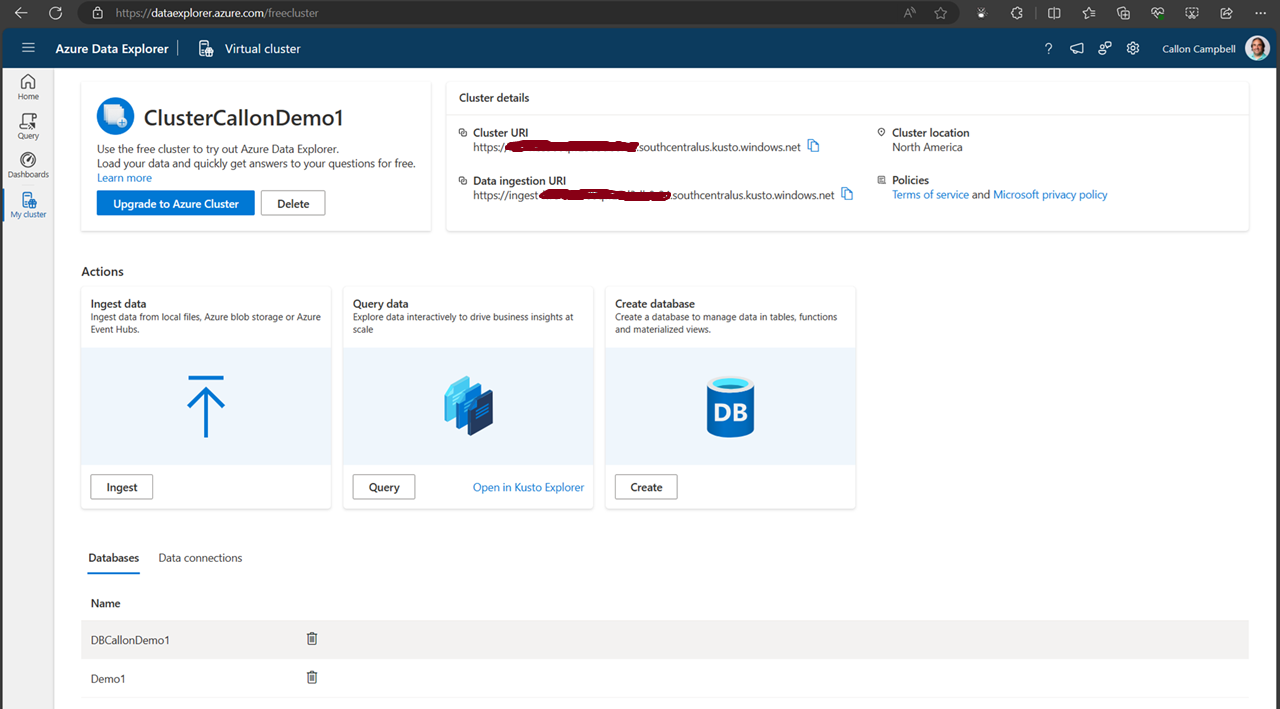
Navigate to the My cluster tab on the left to get access to your cluster URI.
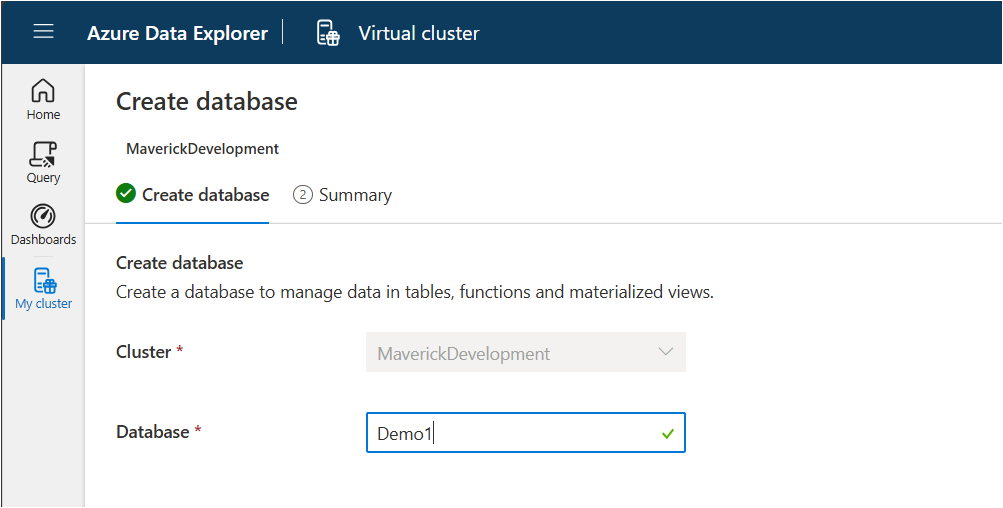
Next, let’s create a new database. While on the My cluster tab, click on the create database button. Give your database a name. In this case, I’m using ‘Demo1’ and then click on the ‘NextCreateDatebase’ button.
Now navigate over to the Query table and lets create our first table, insert some data and run some queries.
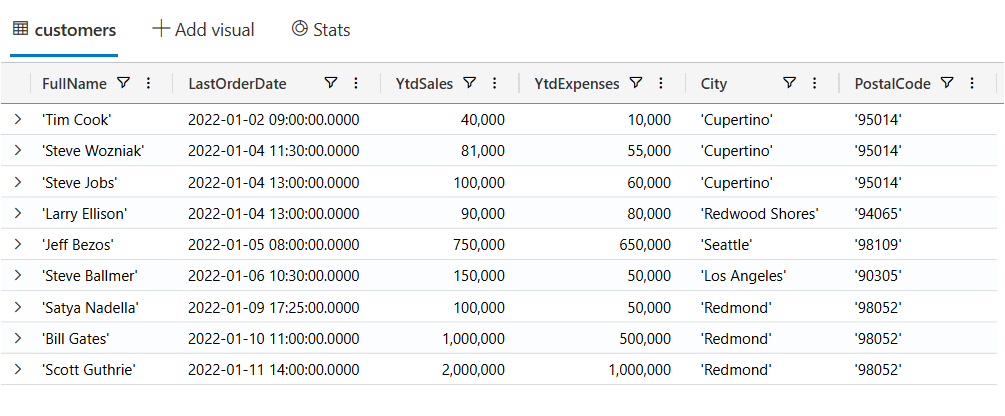
Now, let’s start writing KQL queries against our data. In the following query I’m just using the name of the table with no where clause. This is similar to the “SELECT * FROM Customers” in SQL.
customers
Now let’s filter our data looking for customers where the YtdSales is less than $100,000:
customers
| where YtdSales < 100000
SQL to KQL
If you’re unfamiliar with KQL but are familiar with SQL and want to learn KQL, you can translate your SQL queries into KQL by prefacing the SQL query with a comment line, --, and the keyword explain. The output shows the KQL version of the query, which can help you understand the KQL syntax and concepts. Here is an example of the ‘EXPLAIN’ operator as follows:
In this post we looked at what Azure Data Explorer is, when it should be used, how to use the free personal cluster to create a sample database and ingest data and the run some queries. I hope this was insightful and I look forward to my next post where I’ll go deeper on ingesting data in real-time and running more complicated queries and how we can access this data from dashboards and APIs.