Category: Analytics
Kusto’s 10-Year Evolution at Microsoft
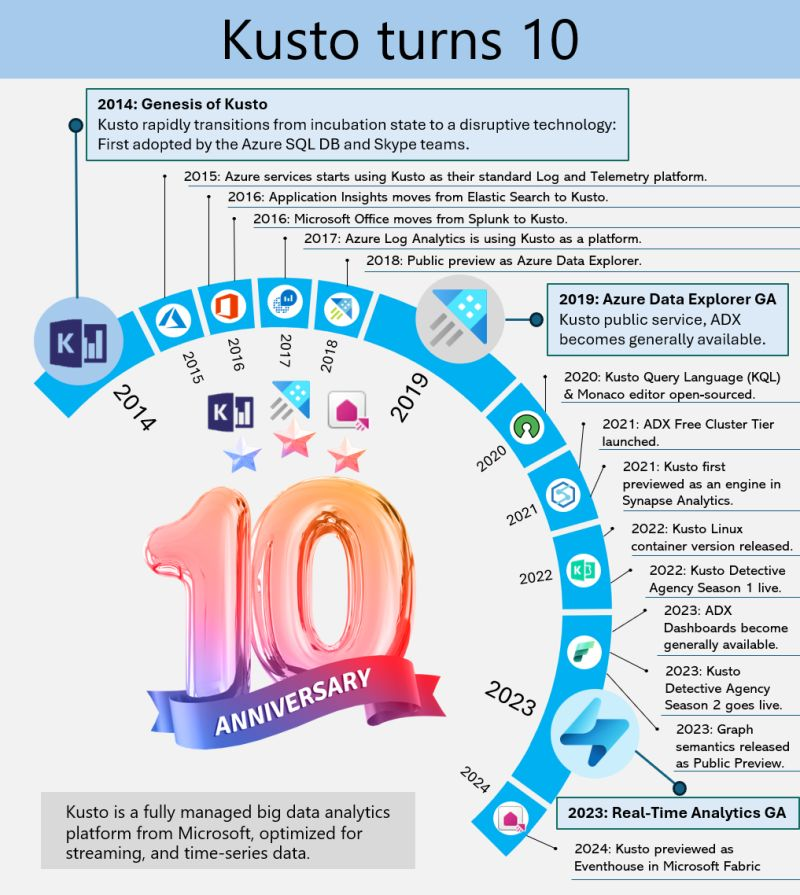
Kusto, the internal service driving Microsoft’s telemetry and several key services, recently marked its 10-year milestone. Over the decade, Kusto has evolved significantly, becoming the backbone for crucial applications such as Sentinel, Application Insights, Azure Data Explorer, and more recently, Eventhouse in Microsoft Fabric. This journey highlights its pivotal role in enhancing data processing, monitoring, and analytics across Microsoft’s ecosystem.
This powerful service has continually adapted to meet the growing demands of Microsoft’s internal and external data needs, underscoring its importance in the company’s broader strategy for data management and analysis.
A Dive into Azure Data Explorer’s Origins
Azure Data Explorer (ADX), initially code-named “Kusto,” has a fascinating backstory. In 2014, it began as a grassroots initiative at Microsoft’s Israel R&D center. The team wanted a name that resonated with their mission of exploring vast data oceans, drawing inspiration from oceanographer Jacques Cousteau. Kusto was designed to tackle the challenges of rapid and scalable log and telemetry analytics, much like Cousteau’s deep-sea explorations.
By 2018, ADX was officially unveiled at the Microsoft Ignite conference, evolving into a fully-managed big data analytics platform. It efficiently handles structured, semi-structured (like JSON), and unstructured data (like free-text). With its powerful querying capabilities and minimal latency, ADX allows users to swiftly explore and analyze data. Remembering its oceanic roots, ADX symbolizes a tribute to the spirit of discovery.
Enjoy!
References
Discovering Insights with Azure Data Explorer
For the past few months, I’ve been diving into learning Azure Data Explorer (ADX) and using it for a few projects. What is Azure Data Explorer, and what would I use it for? Great questions. Azure Data Explorer is like your data’s best friend when it comes to real-time, heavy-duty analytics. It’s built to handle massive amounts of data—whether it’s structured, semi-structured, or all over the place—and turn it into actionable insights. With its star feature, the Kusto Query Language (KQL), you can dive deep into the data for tasks like spotting trends, detecting anomalies, or analyzing logs, all with ease. It’s perfect for high-speed data streams, making it a go-to for IoT and time-series data. Plus, it’s secure, scalable, and does the hard work fast so you can focus on making more intelligent decisions.
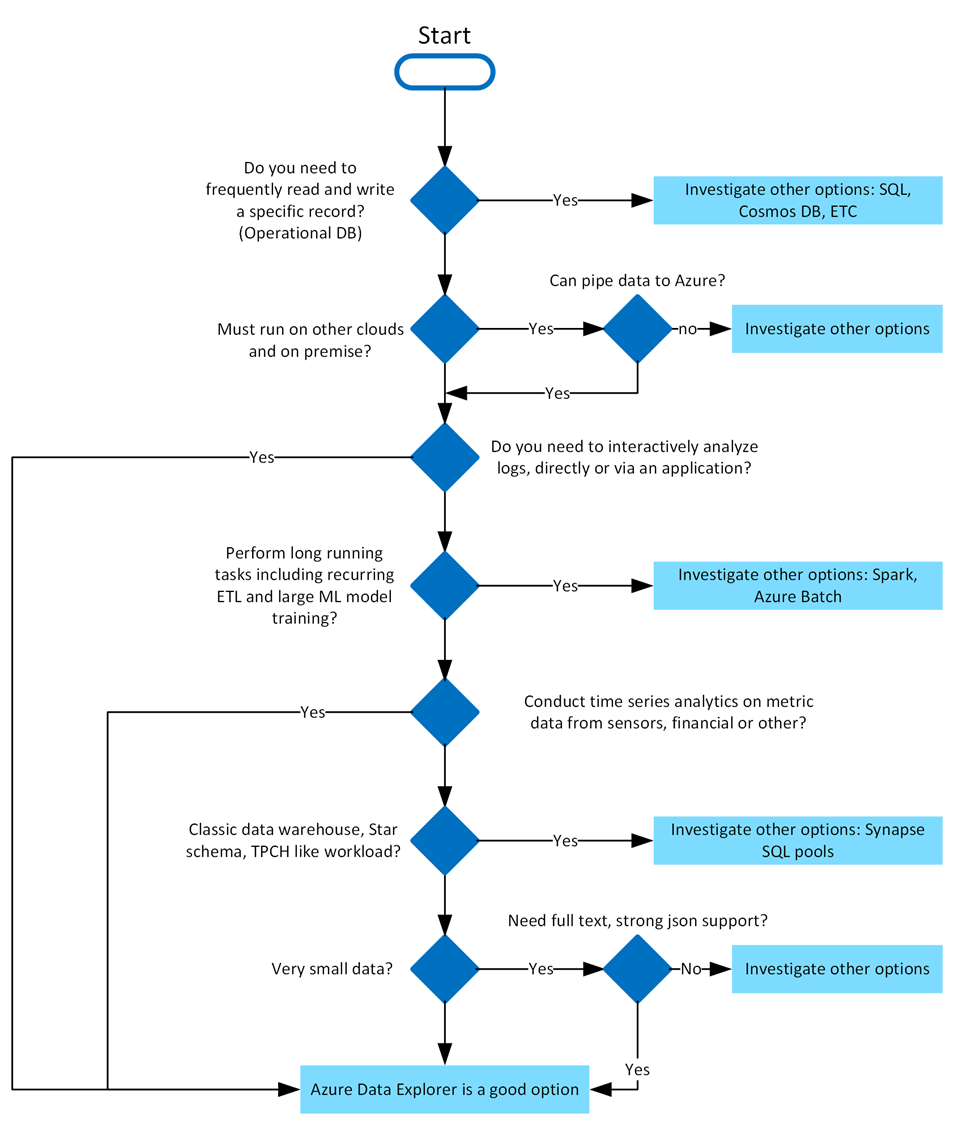
When to use Azure Data Explorer
Azure Data Explorer is ideal for enabling interactive analytics capabilities over high-velocity, diverse raw data. Use the following decision tree to help you decide if Azure Data Explorer is right for you:
What makes Azure Data Explorer unique
Azure Data Explorer stands out due to its exceptional capabilities in handling vast amounts of diverse data quickly and efficiently. It supports high-speed data ingestion (terabytes in minutes) and querying of petabytes with millisecond-level results. Its Kusto Query Language (KQL) is intuitive yet powerful, enabling advanced analytics and seamless integration with Python and T-SQL. With specialized features for time series analysis, anomaly detection, and geospatial insights, it’s tailored for deep data exploration. The platform simplifies data ingestion with its user-friendly wizard, while built-in visualization tools and integrations with Power BI, Grafana, Tableau, and more make insights accessible. It also automates data ingestion, transformation, and export, ensuring a smooth, end-to-end analytics experience.
Writing Kusto queries
In Azure Data Explorer, we use the Kusto Query Language (KQL) to write queries. KQL is also used in other Azure services like Azure Monitor Log Analytics, Azure Sentinel, and many more.
- A Kusto query is a read-only request to process data and return results.
- Has one or more query statements and returns data in a tabular or graph format.
- Statements are sequenced by a pipe (|).
- Data flows, or is piped, from one operator to the next.
- The data is filtered/manipulated at each step and then fed into the following step.
- Each time the data passes through another operator, it’s filtered, rearranged, or summarized.

Here is the above query:
StormEvents
| where StartTime >= datetime(2007-11-01)
| where StartTime <= datetime(2007-12-01)
| where State == 'FLORIDA'
| countAzure Data Explorer query editor also supports the use of T-SQL in addition to its primary query language, Kusto query language (KQL). While KQL is the recommended query language, T-SQL can be useful for tools that are unable to use KQL. For more details, check out how to query data with T-SQL.
Using commands to manage Azure Data Explorer tables
When it comes to writing commands for managing tables, the first character of the text of a request determines if the request is a management command or a query. Management commands must start with the dot (.) character, and no query may start with that character.
Here are some examples of management commands:
- .create table
- .create-merge table
- .drop table
- .alter table
- .rename column
Getting started
You can try Azure Data Explorer for free using the free cluster. Head over to https://dataexplorer.azure.com/ and log in with any Microsoft Account.
Navigate to the My cluster tab on the left to get access to your cluster URI.
Next, let’s create a new database. While on the My cluster tab, click on the create database button. Give your database a name. In this case, I’m using ‘Demo1’ and then click on the ‘NextCreateDatebase’ button.
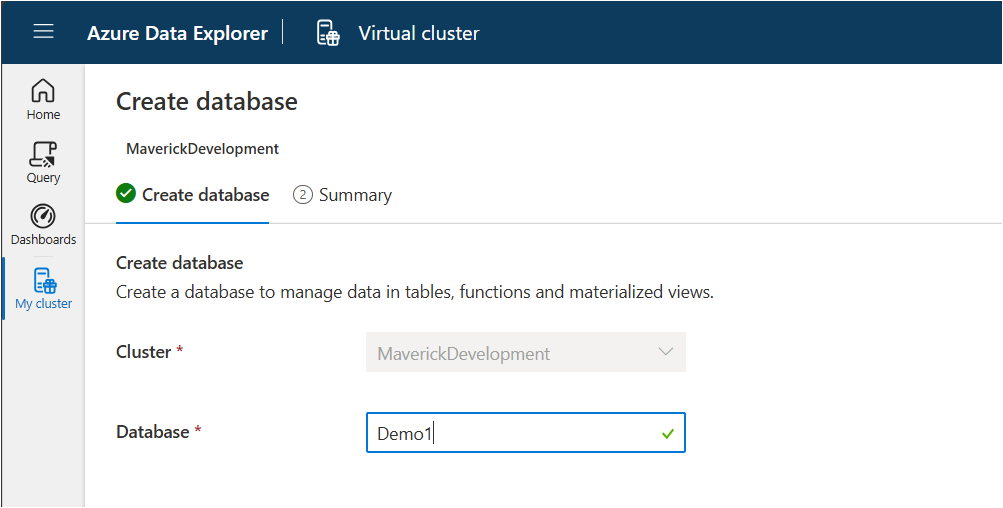
Now navigate over to the Query table and lets create our first table, insert some data and run some queries.
Creating a table
.create-merge table customers
(
FullName: string,
LastOrderDate: datetime,
YtdSales: decimal,
YtdExpenses: decimal,
City: string,
PostalCode: string
)If we run the .show table customers command, we can see the table definition:
.show table customers
Ingesting data
There are several ways we can ingest data into our table. Here are a few options:
- Ingest from Azure Storage
- Ingest from a Query
- Streaming Ingestion
- Ingest Inline
- Ingest from an application
Today we’re going to be using the inline ingestion, which goes as follows:
.ingest inline into table customers <|
'Bill Gates', datetime(2022-01-10 11:00:00), 1000000, 500000, 'Redmond', '98052'
'Steve Ballmer', datetime(2022-01-06 10:30:00), 150000, 50000, 'Los Angeles', '90305'
'Satya Nadella', datetime(2022-01-09 17:25:00), 100000, 50000, 'Redmond', '98052'
'Steve Jobs', datetime(2022-01-04 13:00:00), 100000, 60000, 'Cupertino', '95014'
'Larry Ellison', datetime(2022-01-04 13:00:00), 90000, 80000, 'Redwood Shores', '94065'
'Jeff Bezos', datetime(2022-01-05 08:00:00), 750000, 650000, 'Seattle', '98109'
'Tim Cook', datetime(2022-01-02 09:00:00), 40000, 10000, 'Cupertino', '95014'
'Steve Wozniak', datetime(2022-01-04 11:30:00), 81000, 55000, 'Cupertino', '95014'
'Scott Guthrie', datetime(2022-01-11 14:00:00), 2000000, 1000000, 'Redmond', '98052'Querying data
Now, let’s start writing KQL queries against our data. In the following query I’m just using the name of the table with no where clause. This is similar to the “SELECT * FROM Customers” in SQL.
customers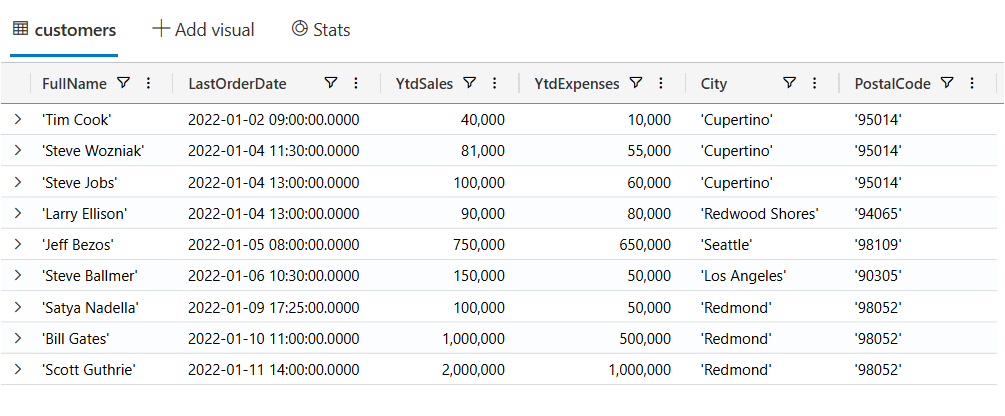
Now let’s filter our data looking for customers where the YtdSales is less than $100,000:
customers
| where YtdSales < 100000
SQL to KQL
If you’re unfamiliar with KQL but are familiar with SQL and want to learn KQL, you can translate your SQL queries into KQL by prefacing the SQL query with a comment line, --, and the keyword explain. The output shows the KQL version of the query, which can help you understand the KQL syntax and concepts. Here is an example of the ‘EXPLAIN’ operator as follows:

Try the SQL to Kusto Query Language cheat sheet.
Wrapping up
In this post we looked at what Azure Data Explorer is, when it should be used, how to use the free personal cluster to create a sample database and ingest data and the run some queries. I hope this was insightful and I look forward to my next post where I’ll go deeper on ingesting data in real-time and running more complicated queries and how we can access this data from dashboards and APIs.
Enjoy!
References
Highlights from Microsoft Build 2021 | Digital Event

I’m happy to announce a Highlights from Microsoft Build 2021 digital event next Thursday, July 15. Please join me and other local experts as we look to provide key insights from the event that will help you expand your skillset, find technical solutions, and innovate for the challenges of tomorrow.
Here are the topics that will be covered:
- .NET 6 and ASP.NET Core 6 and C#10
- Internet of Things
- DevOps
- Kubernetes
- Power Platform
- Artificial Intelligence
- Azure Functions
- Entity Framework
- Power BI
For more details about this event, please visit https://www.meetup.com/CTTDNUG/events/279130746/
Enjoy!
Monitoring and Scaling your Azure Functions
Everybody loves Azure Functions. My team recently deployed a production service using Azure Functions as the back end backbone. I’d like to share some lessons and tips we learned along the way. We’re using Azure functions in consumption plan – which basically means the platform scales in and out as required without our intervention. But […]
Sad to hear that MarkedUp is Shutting Down
I just received an email that MarkedUp is Shutting Down. That is sad to hear, it was a great service.
